class: center <img src="images/gif_serie.gif" width="40%" /> # Sknifedatar **Ajuste y visualización de múltiples modelos** **sobre múltiples series de tiempo** <br> <br> <br> 2021-06-24 Rafael Zambrano & Karina Bartolomé <br> --- <style type="text/css"> /* Table width = 100% max-width */ .remark-slide table{width: 100%;} /* Change the background color to white for shaded rows (even rows) */ .remark-slide thead, .remark-slide tr:nth-child(2n) { background-color: white; .tfoot .td {background-color: white} } .bold-last-item > ul > li:last-of-type, .bold-last-item > ol > li:last-of-type {font-weight: bold;} </style> # ¿Quiénes somos? .pull-left[ ### Rafael Zambrano - Actuario 🇻🇪 - Data Scientist en Ualá 🚀 - Magister en métodos cuantitativos (en curso) ] .pull-right[ <br> <br> <img src="images/imagen_b.jpeg" width="35%" style="display: block; margin: auto;" /> ] .pull-left[ ### Karina Bartolomé - Economista 🇦🇷 - Data Scientist en Ualá 🚀 - Especialista en métodos cuantitativos (en curso) ] .pull-right[ <br> <br> <img src="images/imagen_a.jpeg" width="35%" style="display: block; margin: auto;" /> ] --- # ¿Qué es #modeltime? Es un ecosistema desarrollado por **Matt Dancho** para realizar análisis de series de tiempo mediante un enfoque ordenado (o Tidy) con #tidymodels 📦. <img src="images/modeltime.png" width="90%" height="90%" style="display: block; margin: auto;" /> --- # Sknifedatar 📦 #### Una extensión de **#modeltime** ```r install.packages('sknifedatar') ``` -- <img src="images/sknifedatar.png" width="20%" height="20%" style="display: block; margin: auto;" /> Incluye: - **Funciones multifit**: Múltiples modelos en múltiples series de tiempo (sin datos de panel) - **Workflowsets**: Ajuste de múltiples modelos y recetas de preprocesamiento con modeltime - **Workflowset multifit**: Ajuste de múltiples modelos y recetas de preprocesamiento sobre múltiples modelos (sin datos de panel) - **Automagic tabs**: Generación automática de tabs --- # Agenda para hoy <img src="images/gif_gato_lentes.gif" width="30%" style="display: block; margin: auto;" /> - **Introducción a modeltime** - **Multifit**: Ajuste de múltiples modelos en múltiples series de tiempo - **Workflowsets**: Ajuste de múltiples modelos y recetas de preprocesamiento sobre múltiples modelos - **Automagic tabs**: Generación automática de tabs en Distill / Rmd --- # Librerías utilizadas 📚 ```r library(sknifedatar) library(modeltime) library(workflowsets) library(tidymodels) library(tidyverse) library(timetk) library(anomalize) ``` <img src="images/gif_libros.gif" width="50%" style="display: block; margin: auto;" /> --- # Datos 📊 **Consumo residencial de gas 4 estados de Estados Unidos, entre 1989 y 2020** -- ```r data <- USgas::us_residential %>% rename(value=y) %>% filter(state %in% c('Nevada','Maine', 'Hawaii','West Virginia')) %>% group_by(state) %>% mutate(value = ifelse(is.na(value),mean(value, na.rm=TRUE),value)) %>% ungroup() ``` -- <table> <thead> <tr> <th style="text-align:left;"> date </th> <th style="text-align:left;"> state </th> <th style="text-align:right;"> value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> 1989-01-01 </td> <td style="text-align:left;"> Hawaii </td> <td style="text-align:right;"> 51 </td> </tr> <tr> <td style="text-align:left;"> 1989-02-01 </td> <td style="text-align:left;"> Hawaii </td> <td style="text-align:right;"> 52 </td> </tr> <tr> <td style="text-align:left;"> 1989-03-01 </td> <td style="text-align:left;"> Hawaii </td> <td style="text-align:right;"> 50 </td> </tr> <tr> <td style="text-align:left;"> 1989-04-01 </td> <td style="text-align:left;"> Hawaii </td> <td style="text-align:right;"> 50 </td> </tr> <tr> <td style="text-align:left;"> 1989-05-01 </td> <td style="text-align:left;"> Hawaii </td> <td style="text-align:right;"> 47 </td> </tr> </tbody> </table> --- ### Evolución 📈 ```r data %>% group_by(state) %>% plot_time_series(date, value) ``` 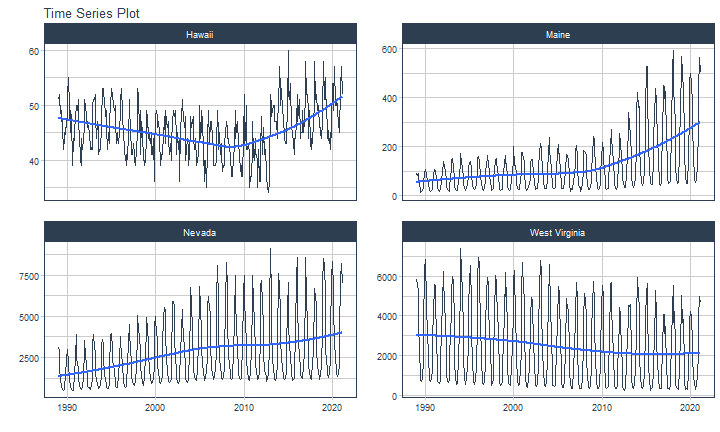<!-- --> --- ### Detección de anomalías 🔍 ```r data %>% group_by(state) %>% plot_anomaly_diagnostics(date, value) ``` 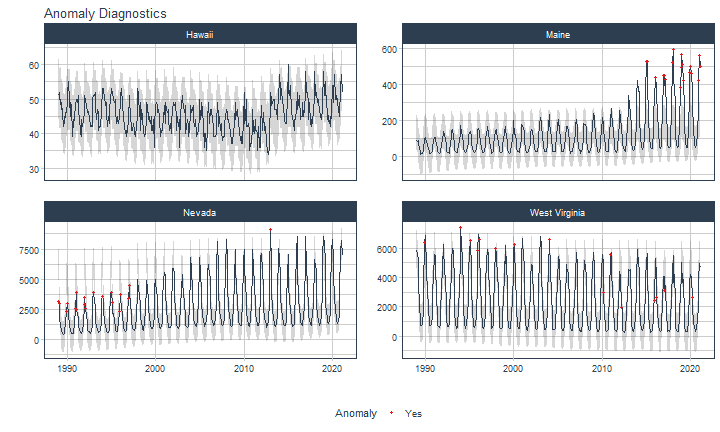<!-- --> --- ### Descomposición de series de tiempo .panelset[ .panel[.panel-name[Hawaii] 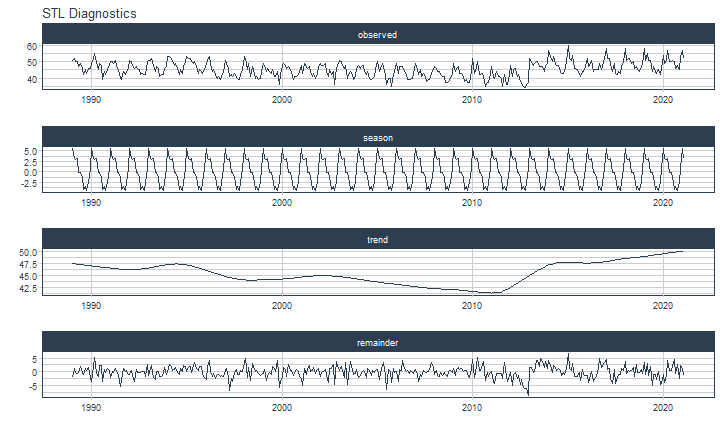<!-- --> ] .panel[.panel-name[Maine] 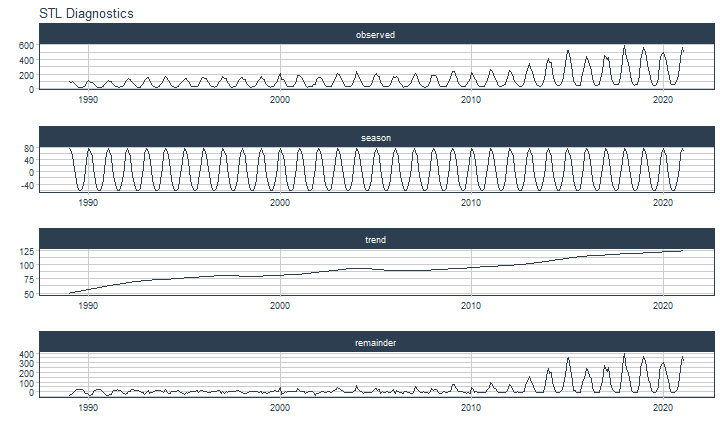<!-- --> ] .panel[.panel-name[Nevada] 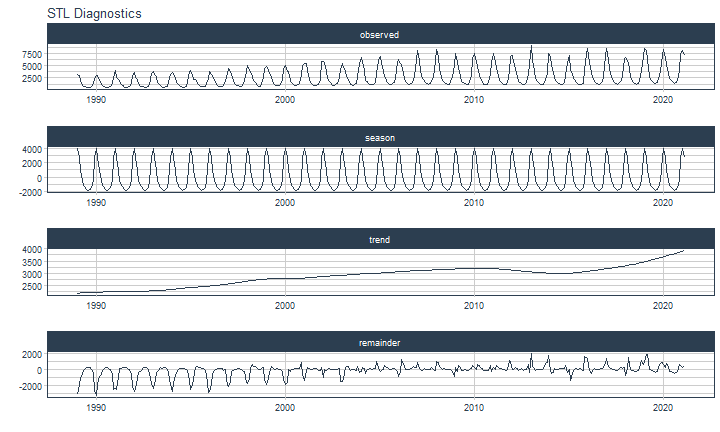<!-- --> ] .panel[.panel-name[West Virginia] 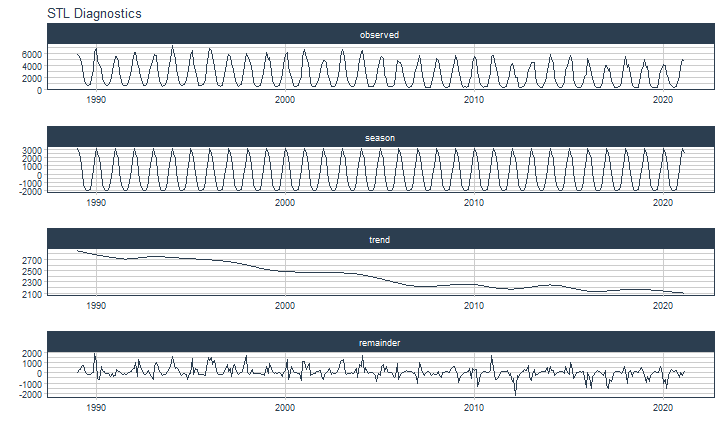<!-- --> ] ] --- <br> <br> # Múltiples modelos y una serie <br> <img src="images/gif_gatos_multi.gif" width="25%" style="display: block; margin: auto;" /> --- ## Flujo de trabajo de modeltime ### Preparación de datos ⚙️ * Se selecciona el estado de 🏖 **Hawaii** ```r data_hawaii <- data %>% filter(state=='Hawaii') ``` -- * Particiona el dataset en train y test ✂️ ```r splits <- data_hawaii %>% initial_time_split(prop = 0.8) ``` --- ### Visualización de la partición ```r splits %>% tk_time_series_cv_plan() %>% plot_time_series_cv_plan(date, value) ``` <div id="htmlwidget-3dbb2dbf291f389f0c02" style="width:720px;height:432px;" class="plotly html-widget"></div> <script type="application/json" data-for="htmlwidget-3dbb2dbf291f389f0c02">{"x":{"data":[{"x":["1989-01-01","1989-02-01","1989-03-01","1989-04-01","1989-05-01","1989-06-01","1989-07-01","1989-08-01","1989-09-01","1989-10-01","1989-11-01","1989-12-01","1990-01-01","1990-02-01","1990-03-01","1990-04-01","1990-05-01","1990-06-01","1990-07-01","1990-08-01","1990-09-01","1990-10-01","1990-11-01","1990-12-01","1991-01-01","1991-02-01","1991-03-01","1991-04-01","1991-05-01","1991-06-01","1991-07-01","1991-08-01","1991-09-01","1991-10-01","1991-11-01","1991-12-01","1992-01-01","1992-02-01","1992-03-01","1992-04-01","1992-05-01","1992-06-01","1992-07-01","1992-08-01","1992-09-01","1992-10-01","1992-11-01","1992-12-01","1993-01-01","1993-02-01","1993-03-01","1993-04-01","1993-05-01","1993-06-01","1993-07-01","1993-08-01","1993-09-01","1993-10-01","1993-11-01","1993-12-01","1994-01-01","1994-02-01","1994-03-01","1994-04-01","1994-05-01","1994-06-01","1994-07-01","1994-08-01","1994-09-01","1994-10-01","1994-11-01","1994-12-01","1995-01-01","1995-02-01","1995-03-01","1995-04-01","1995-05-01","1995-06-01","1995-07-01","1995-08-01","1995-09-01","1995-10-01","1995-11-01","1995-12-01","1996-01-01","1996-02-01","1996-03-01","1996-04-01","1996-05-01","1996-06-01","1996-07-01","1996-08-01","1996-09-01","1996-10-01","1996-11-01","1996-12-01","1997-01-01","1997-02-01","1997-03-01","1997-04-01","1997-05-01","1997-06-01","1997-07-01","1997-08-01","1997-09-01","1997-10-01","1997-11-01","1997-12-01","1998-01-01","1998-02-01","1998-03-01","1998-04-01","1998-05-01","1998-06-01","1998-07-01","1998-08-01","1998-09-01","1998-10-01","1998-11-01","1998-12-01","1999-01-01","1999-02-01","1999-03-01","1999-04-01","1999-05-01","1999-06-01","1999-07-01","1999-08-01","1999-09-01","1999-10-01","1999-11-01","1999-12-01","2000-01-01","2000-02-01","2000-03-01","2000-04-01","2000-05-01","2000-06-01","2000-07-01","2000-08-01","2000-09-01","2000-10-01","2000-11-01","2000-12-01","2001-01-01","2001-02-01","2001-03-01","2001-04-01","2001-05-01","2001-06-01","2001-07-01","2001-08-01","2001-09-01","2001-10-01","2001-11-01","2001-12-01","2002-01-01","2002-02-01","2002-03-01","2002-04-01","2002-05-01","2002-06-01","2002-07-01","2002-08-01","2002-09-01","2002-10-01","2002-11-01","2002-12-01","2003-01-01","2003-02-01","2003-03-01","2003-04-01","2003-05-01","2003-06-01","2003-07-01","2003-08-01","2003-09-01","2003-10-01","2003-11-01","2003-12-01","2004-01-01","2004-02-01","2004-03-01","2004-04-01","2004-05-01","2004-06-01","2004-07-01","2004-08-01","2004-09-01","2004-10-01","2004-11-01","2004-12-01","2005-01-01","2005-02-01","2005-03-01","2005-04-01","2005-05-01","2005-06-01","2005-07-01","2005-08-01","2005-09-01","2005-10-01","2005-11-01","2005-12-01","2006-01-01","2006-02-01","2006-03-01","2006-04-01","2006-05-01","2006-06-01","2006-07-01","2006-08-01","2006-09-01","2006-10-01","2006-11-01","2006-12-01","2007-01-01","2007-02-01","2007-03-01","2007-04-01","2007-05-01","2007-06-01","2007-07-01","2007-08-01","2007-09-01","2007-10-01","2007-11-01","2007-12-01","2008-01-01","2008-02-01","2008-03-01","2008-04-01","2008-05-01","2008-06-01","2008-07-01","2008-08-01","2008-09-01","2008-10-01","2008-11-01","2008-12-01","2009-01-01","2009-02-01","2009-03-01","2009-04-01","2009-05-01","2009-06-01","2009-07-01","2009-08-01","2009-09-01","2009-10-01","2009-11-01","2009-12-01","2010-01-01","2010-02-01","2010-03-01","2010-04-01","2010-05-01","2010-06-01","2010-07-01","2010-08-01","2010-09-01","2010-10-01","2010-11-01","2010-12-01","2011-01-01","2011-02-01","2011-03-01","2011-04-01","2011-05-01","2011-06-01","2011-07-01","2011-08-01","2011-09-01","2011-10-01","2011-11-01","2011-12-01","2012-01-01","2012-02-01","2012-03-01","2012-04-01","2012-05-01","2012-06-01","2012-07-01","2012-08-01","2012-09-01","2012-10-01","2012-11-01","2012-12-01","2013-01-01","2013-02-01","2013-03-01","2013-04-01","2013-05-01","2013-06-01","2013-07-01","2013-08-01","2013-09-01","2013-10-01","2013-11-01","2013-12-01","2014-01-01","2014-02-01","2014-03-01","2014-04-01","2014-05-01","2014-06-01","2014-07-01","2014-08-01"],"y":[51,52,50,50,47,49,46,42,45,43,46,46,49,52,55,50,45,49,48,39,44,42,45,48,50,50,49,51,46,45,40,39,44,42,44,46,51,50,48,46,47,46,45,42,43,42,42,50,51,51,52,48,44,47,46,41,42,42,46,47,53,53,52,51,48,49,46,42,45,43,47,50,53,52,52,50,49,50,47,43,45,44,43,45,49,51,53,49,44,45,42,40,41,39,41,44,51,49,46,41,42,41,43,41,40,39,42,45,53,52,45,49,41,47,45,40,41,39,40,44,49,48,44,46,44,43,45,41,41,44,36,42,48,49,48,46,47,45,44,39,41,41,42,44,48,43,49,47,46,47,44,41,43,40,43,47,49,48,48,49,44,41,45,42,44,36,46,48,51,50,48,46,48,40,42,44,42,39,41,46,48,46,47,48,44,42,44,40,39,40,41,45,50,44,46,49,47,42,36,40,40,35,42,44,49,43,47,47,47,44,42,39,39,39,40,43,49,45,42,45,41,43,41,38,39,39,43,45,47,46,44,44,42,41,41,37,37,38,40,43,49,44,46,47,43,43,41,38,39,37,37,44,52,43,44,50,42,42,43,41,35,37,37,42,47,41,40,44,41,41,40,35,42,36,36,42,48,41,45,46,41,42,38,37,35,34,36,37,52,50,48,49,50,50,47,47,47,44,48,49,57,53,50,53,49,48,48,44],"text":["date: 1989-01-01<br />.value: 51<br />.color_mod: training<br />.color_mod: training","date: 1989-02-01<br />.value: 52<br />.color_mod: training<br />.color_mod: training","date: 1989-03-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 1989-04-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 1989-05-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 1989-06-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1989-07-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1989-08-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1989-09-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1989-10-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 1989-11-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1989-12-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1990-01-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1990-02-01<br />.value: 52<br />.color_mod: training<br />.color_mod: training","date: 1990-03-01<br />.value: 55<br />.color_mod: training<br />.color_mod: training","date: 1990-04-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 1990-05-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1990-06-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1990-07-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 1990-08-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 1990-09-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1990-10-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1990-11-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1990-12-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 1991-01-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 1991-02-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 1991-03-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1991-04-01<br />.value: 51<br />.color_mod: training<br />.color_mod: training","date: 1991-05-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1991-06-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1991-07-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 1991-08-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 1991-09-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1991-10-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1991-11-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1991-12-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1992-01-01<br />.value: 51<br />.color_mod: training<br />.color_mod: training","date: 1992-02-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 1992-03-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 1992-04-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1992-05-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 1992-06-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1992-07-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1992-08-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1992-09-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 1992-10-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1992-11-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1992-12-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 1993-01-01<br />.value: 51<br />.color_mod: training<br />.color_mod: training","date: 1993-02-01<br />.value: 51<br />.color_mod: training<br />.color_mod: training","date: 1993-03-01<br />.value: 52<br />.color_mod: training<br />.color_mod: training","date: 1993-04-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 1993-05-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1993-06-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 1993-07-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1993-08-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 1993-09-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1993-10-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1993-11-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1993-12-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 1994-01-01<br />.value: 53<br />.color_mod: training<br />.color_mod: training","date: 1994-02-01<br />.value: 53<br />.color_mod: training<br />.color_mod: training","date: 1994-03-01<br />.value: 52<br />.color_mod: training<br />.color_mod: training","date: 1994-04-01<br />.value: 51<br />.color_mod: training<br />.color_mod: training","date: 1994-05-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 1994-06-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1994-07-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1994-08-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1994-09-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1994-10-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 1994-11-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 1994-12-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 1995-01-01<br />.value: 53<br />.color_mod: training<br />.color_mod: training","date: 1995-02-01<br />.value: 52<br />.color_mod: training<br />.color_mod: training","date: 1995-03-01<br />.value: 52<br />.color_mod: training<br />.color_mod: training","date: 1995-04-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 1995-05-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1995-06-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 1995-07-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 1995-08-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 1995-09-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1995-10-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1995-11-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 1995-12-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1996-01-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1996-02-01<br />.value: 51<br />.color_mod: training<br />.color_mod: training","date: 1996-03-01<br />.value: 53<br />.color_mod: training<br />.color_mod: training","date: 1996-04-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1996-05-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1996-06-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1996-07-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1996-08-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 1996-09-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 1996-10-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 1996-11-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 1996-12-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1997-01-01<br />.value: 51<br />.color_mod: training<br />.color_mod: training","date: 1997-02-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1997-03-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1997-04-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 1997-05-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1997-06-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 1997-07-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 1997-08-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 1997-09-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 1997-10-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 1997-11-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 1997-12-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1998-01-01<br />.value: 53<br />.color_mod: training<br />.color_mod: training","date: 1998-02-01<br />.value: 52<br />.color_mod: training<br />.color_mod: training","date: 1998-03-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1998-04-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1998-05-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 1998-06-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 1998-07-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1998-08-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 1998-09-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 1998-10-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 1998-11-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 1998-12-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1999-01-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 1999-02-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 1999-03-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1999-04-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 1999-05-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1999-06-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 1999-07-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 1999-08-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 1999-09-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 1999-10-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 1999-11-01<br />.value: 36<br />.color_mod: training<br />.color_mod: training","date: 1999-12-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2000-01-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2000-02-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2000-03-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2000-04-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 2000-05-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2000-06-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 2000-07-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2000-08-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 2000-09-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2000-10-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2000-11-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2000-12-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2001-01-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2001-02-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2001-03-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2001-04-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2001-05-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 2001-06-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2001-07-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2001-08-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2001-09-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2001-10-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 2001-11-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2001-12-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2002-01-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2002-02-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2002-03-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2002-04-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2002-05-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2002-06-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2002-07-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 2002-08-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2002-09-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2002-10-01<br />.value: 36<br />.color_mod: training<br />.color_mod: training","date: 2002-11-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 2002-12-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2003-01-01<br />.value: 51<br />.color_mod: training<br />.color_mod: training","date: 2003-02-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 2003-03-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2003-04-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 2003-05-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2003-06-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 2003-07-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2003-08-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2003-09-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2003-10-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 2003-11-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2003-12-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 2004-01-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2004-02-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 2004-03-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2004-04-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2004-05-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2004-06-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2004-07-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2004-08-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 2004-09-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 2004-10-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 2004-11-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2004-12-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 2005-01-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 2005-02-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2005-03-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 2005-04-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2005-05-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2005-06-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2005-07-01<br />.value: 36<br />.color_mod: training<br />.color_mod: training","date: 2005-08-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 2005-09-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 2005-10-01<br />.value: 35<br />.color_mod: training<br />.color_mod: training","date: 2005-11-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2005-12-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2006-01-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2006-02-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2006-03-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2006-04-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2006-05-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2006-06-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2006-07-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2006-08-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 2006-09-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 2006-10-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 2006-11-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 2006-12-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2007-01-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2007-02-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 2007-03-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2007-04-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 2007-05-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2007-06-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2007-07-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2007-08-01<br />.value: 38<br />.color_mod: training<br />.color_mod: training","date: 2007-09-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 2007-10-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 2007-11-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2007-12-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 2008-01-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2008-02-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 2008-03-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2008-04-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2008-05-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2008-06-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2008-07-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2008-08-01<br />.value: 37<br />.color_mod: training<br />.color_mod: training","date: 2008-09-01<br />.value: 37<br />.color_mod: training<br />.color_mod: training","date: 2008-10-01<br />.value: 38<br />.color_mod: training<br />.color_mod: training","date: 2008-11-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 2008-12-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2009-01-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2009-02-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2009-03-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 2009-04-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2009-05-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2009-06-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2009-07-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2009-08-01<br />.value: 38<br />.color_mod: training<br />.color_mod: training","date: 2009-09-01<br />.value: 39<br />.color_mod: training<br />.color_mod: training","date: 2009-10-01<br />.value: 37<br />.color_mod: training<br />.color_mod: training","date: 2009-11-01<br />.value: 37<br />.color_mod: training<br />.color_mod: training","date: 2009-12-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2010-01-01<br />.value: 52<br />.color_mod: training<br />.color_mod: training","date: 2010-02-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2010-03-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2010-04-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 2010-05-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2010-06-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2010-07-01<br />.value: 43<br />.color_mod: training<br />.color_mod: training","date: 2010-08-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2010-09-01<br />.value: 35<br />.color_mod: training<br />.color_mod: training","date: 2010-10-01<br />.value: 37<br />.color_mod: training<br />.color_mod: training","date: 2010-11-01<br />.value: 37<br />.color_mod: training<br />.color_mod: training","date: 2010-12-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2011-01-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2011-02-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2011-03-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 2011-04-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2011-05-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2011-06-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2011-07-01<br />.value: 40<br />.color_mod: training<br />.color_mod: training","date: 2011-08-01<br />.value: 35<br />.color_mod: training<br />.color_mod: training","date: 2011-09-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2011-10-01<br />.value: 36<br />.color_mod: training<br />.color_mod: training","date: 2011-11-01<br />.value: 36<br />.color_mod: training<br />.color_mod: training","date: 2011-12-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2012-01-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2012-02-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2012-03-01<br />.value: 45<br />.color_mod: training<br />.color_mod: training","date: 2012-04-01<br />.value: 46<br />.color_mod: training<br />.color_mod: training","date: 2012-05-01<br />.value: 41<br />.color_mod: training<br />.color_mod: training","date: 2012-06-01<br />.value: 42<br />.color_mod: training<br />.color_mod: training","date: 2012-07-01<br />.value: 38<br />.color_mod: training<br />.color_mod: training","date: 2012-08-01<br />.value: 37<br />.color_mod: training<br />.color_mod: training","date: 2012-09-01<br />.value: 35<br />.color_mod: training<br />.color_mod: training","date: 2012-10-01<br />.value: 34<br />.color_mod: training<br />.color_mod: training","date: 2012-11-01<br />.value: 36<br />.color_mod: training<br />.color_mod: training","date: 2012-12-01<br />.value: 37<br />.color_mod: training<br />.color_mod: training","date: 2013-01-01<br />.value: 52<br />.color_mod: training<br />.color_mod: training","date: 2013-02-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 2013-03-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2013-04-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2013-05-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 2013-06-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 2013-07-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2013-08-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2013-09-01<br />.value: 47<br />.color_mod: training<br />.color_mod: training","date: 2013-10-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training","date: 2013-11-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2013-12-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2014-01-01<br />.value: 57<br />.color_mod: training<br />.color_mod: training","date: 2014-02-01<br />.value: 53<br />.color_mod: training<br />.color_mod: training","date: 2014-03-01<br />.value: 50<br />.color_mod: training<br />.color_mod: training","date: 2014-04-01<br />.value: 53<br />.color_mod: training<br />.color_mod: training","date: 2014-05-01<br />.value: 49<br />.color_mod: training<br />.color_mod: training","date: 2014-06-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2014-07-01<br />.value: 48<br />.color_mod: training<br />.color_mod: training","date: 2014-08-01<br />.value: 44<br />.color_mod: training<br />.color_mod: training"],"type":"scatter","mode":"lines","line":{"width":1.88976377952756,"color":"rgba(44,62,80,1)","dash":"solid"},"hoveron":"points","name":"training","legendgroup":"training","showlegend":true,"xaxis":"x","yaxis":"y","hoverinfo":"text","frame":null},{"x":["2014-09-01","2014-10-01","2014-11-01","2014-12-01","2015-01-01","2015-02-01","2015-03-01","2015-04-01","2015-05-01","2015-06-01","2015-07-01","2015-08-01","2015-09-01","2015-10-01","2015-11-01","2015-12-01","2016-01-01","2016-02-01","2016-03-01","2016-04-01","2016-05-01","2016-06-01","2016-07-01","2016-08-01","2016-09-01","2016-10-01","2016-11-01","2016-12-01","2017-01-01","2017-02-01","2017-03-01","2017-04-01","2017-05-01","2017-06-01","2017-07-01","2017-08-01","2017-09-01","2017-10-01","2017-11-01","2017-12-01","2018-01-01","2018-02-01","2018-03-01","2018-04-01","2018-05-01","2018-06-01","2018-07-01","2018-08-01","2018-09-01","2018-10-01","2018-11-01","2018-12-01","2019-01-01","2019-02-01","2019-03-01","2019-04-01","2019-05-01","2019-06-01","2019-07-01","2019-08-01","2019-09-01","2019-10-01","2019-11-01","2019-12-01","2020-01-01","2020-02-01","2020-03-01","2020-04-01","2020-05-01","2020-06-01","2020-07-01","2020-08-01","2020-09-01","2020-10-01","2020-11-01","2020-12-01","2021-01-01","2021-02-01"],"y":[43,43,44,50,60,52,51,54,46,46,45,43,41,44,44,47,52,47,49,51,44,45,45,45,49,45,47,52,58,52,52,49,44,49,43,42,44,43,47,50,58,51,52,52,49,50,46,47,45,44,47,49,58,51,55,51,51,44,47,44,43,45,42,46,54,49,51,57,50,50,51,50,46,48,45,53,57,52],"text":["date: 2014-09-01<br />.value: 43<br />.color_mod: testing<br />.color_mod: testing","date: 2014-10-01<br />.value: 43<br />.color_mod: testing<br />.color_mod: testing","date: 2014-11-01<br />.value: 44<br />.color_mod: testing<br />.color_mod: testing","date: 2014-12-01<br />.value: 50<br />.color_mod: testing<br />.color_mod: testing","date: 2015-01-01<br />.value: 60<br />.color_mod: testing<br />.color_mod: testing","date: 2015-02-01<br />.value: 52<br />.color_mod: testing<br />.color_mod: testing","date: 2015-03-01<br />.value: 51<br />.color_mod: testing<br />.color_mod: testing","date: 2015-04-01<br />.value: 54<br />.color_mod: testing<br />.color_mod: testing","date: 2015-05-01<br />.value: 46<br />.color_mod: testing<br />.color_mod: testing","date: 2015-06-01<br />.value: 46<br />.color_mod: testing<br />.color_mod: testing","date: 2015-07-01<br />.value: 45<br />.color_mod: testing<br />.color_mod: testing","date: 2015-08-01<br />.value: 43<br />.color_mod: testing<br />.color_mod: testing","date: 2015-09-01<br />.value: 41<br />.color_mod: testing<br />.color_mod: testing","date: 2015-10-01<br />.value: 44<br />.color_mod: testing<br />.color_mod: testing","date: 2015-11-01<br />.value: 44<br />.color_mod: testing<br />.color_mod: testing","date: 2015-12-01<br />.value: 47<br />.color_mod: testing<br />.color_mod: testing","date: 2016-01-01<br />.value: 52<br />.color_mod: testing<br />.color_mod: testing","date: 2016-02-01<br />.value: 47<br />.color_mod: testing<br />.color_mod: testing","date: 2016-03-01<br />.value: 49<br />.color_mod: testing<br />.color_mod: testing","date: 2016-04-01<br />.value: 51<br />.color_mod: testing<br />.color_mod: testing","date: 2016-05-01<br />.value: 44<br />.color_mod: testing<br />.color_mod: testing","date: 2016-06-01<br />.value: 45<br />.color_mod: testing<br />.color_mod: testing","date: 2016-07-01<br />.value: 45<br />.color_mod: testing<br />.color_mod: testing","date: 2016-08-01<br />.value: 45<br />.color_mod: testing<br />.color_mod: testing","date: 2016-09-01<br />.value: 49<br />.color_mod: testing<br />.color_mod: testing","date: 2016-10-01<br />.value: 45<br />.color_mod: testing<br />.color_mod: testing","date: 2016-11-01<br />.value: 47<br />.color_mod: testing<br />.color_mod: testing","date: 2016-12-01<br />.value: 52<br />.color_mod: testing<br />.color_mod: testing","date: 2017-01-01<br />.value: 58<br />.color_mod: testing<br />.color_mod: testing","date: 2017-02-01<br />.value: 52<br />.color_mod: testing<br />.color_mod: testing","date: 2017-03-01<br />.value: 52<br />.color_mod: testing<br />.color_mod: testing","date: 2017-04-01<br />.value: 49<br />.color_mod: testing<br />.color_mod: testing","date: 2017-05-01<br />.value: 44<br />.color_mod: testing<br />.color_mod: testing","date: 2017-06-01<br />.value: 49<br />.color_mod: testing<br />.color_mod: testing","date: 2017-07-01<br />.value: 43<br />.color_mod: testing<br />.color_mod: testing","date: 2017-08-01<br />.value: 42<br />.color_mod: testing<br />.color_mod: testing","date: 2017-09-01<br />.value: 44<br />.color_mod: testing<br />.color_mod: testing","date: 2017-10-01<br />.value: 43<br />.color_mod: testing<br />.color_mod: testing","date: 2017-11-01<br />.value: 47<br />.color_mod: testing<br />.color_mod: testing","date: 2017-12-01<br />.value: 50<br />.color_mod: testing<br />.color_mod: testing","date: 2018-01-01<br />.value: 58<br />.color_mod: testing<br />.color_mod: testing","date: 2018-02-01<br />.value: 51<br />.color_mod: testing<br />.color_mod: testing","date: 2018-03-01<br />.value: 52<br />.color_mod: testing<br />.color_mod: testing","date: 2018-04-01<br />.value: 52<br />.color_mod: testing<br />.color_mod: testing","date: 2018-05-01<br />.value: 49<br />.color_mod: testing<br />.color_mod: testing","date: 2018-06-01<br />.value: 50<br />.color_mod: testing<br />.color_mod: testing","date: 2018-07-01<br />.value: 46<br />.color_mod: testing<br />.color_mod: testing","date: 2018-08-01<br />.value: 47<br />.color_mod: testing<br />.color_mod: testing","date: 2018-09-01<br />.value: 45<br />.color_mod: testing<br />.color_mod: testing","date: 2018-10-01<br />.value: 44<br />.color_mod: testing<br />.color_mod: testing","date: 2018-11-01<br />.value: 47<br />.color_mod: testing<br />.color_mod: testing","date: 2018-12-01<br />.value: 49<br />.color_mod: testing<br />.color_mod: testing","date: 2019-01-01<br />.value: 58<br />.color_mod: testing<br />.color_mod: testing","date: 2019-02-01<br />.value: 51<br />.color_mod: testing<br />.color_mod: testing","date: 2019-03-01<br />.value: 55<br />.color_mod: testing<br />.color_mod: testing","date: 2019-04-01<br />.value: 51<br />.color_mod: testing<br />.color_mod: testing","date: 2019-05-01<br />.value: 51<br />.color_mod: testing<br />.color_mod: testing","date: 2019-06-01<br />.value: 44<br />.color_mod: testing<br />.color_mod: testing","date: 2019-07-01<br />.value: 47<br />.color_mod: testing<br />.color_mod: testing","date: 2019-08-01<br />.value: 44<br />.color_mod: testing<br />.color_mod: testing","date: 2019-09-01<br />.value: 43<br />.color_mod: testing<br />.color_mod: testing","date: 2019-10-01<br />.value: 45<br />.color_mod: testing<br />.color_mod: testing","date: 2019-11-01<br />.value: 42<br />.color_mod: testing<br />.color_mod: testing","date: 2019-12-01<br />.value: 46<br />.color_mod: testing<br />.color_mod: testing","date: 2020-01-01<br />.value: 54<br />.color_mod: testing<br />.color_mod: testing","date: 2020-02-01<br />.value: 49<br />.color_mod: testing<br />.color_mod: testing","date: 2020-03-01<br />.value: 51<br />.color_mod: testing<br />.color_mod: testing","date: 2020-04-01<br />.value: 57<br />.color_mod: testing<br />.color_mod: testing","date: 2020-05-01<br />.value: 50<br />.color_mod: testing<br />.color_mod: testing","date: 2020-06-01<br />.value: 50<br />.color_mod: testing<br />.color_mod: testing","date: 2020-07-01<br />.value: 51<br />.color_mod: testing<br />.color_mod: testing","date: 2020-08-01<br />.value: 50<br />.color_mod: testing<br />.color_mod: testing","date: 2020-09-01<br />.value: 46<br />.color_mod: testing<br />.color_mod: testing","date: 2020-10-01<br />.value: 48<br />.color_mod: testing<br />.color_mod: testing","date: 2020-11-01<br />.value: 45<br />.color_mod: testing<br />.color_mod: testing","date: 2020-12-01<br />.value: 53<br />.color_mod: testing<br />.color_mod: testing","date: 2021-01-01<br />.value: 57<br />.color_mod: testing<br />.color_mod: testing","date: 2021-02-01<br />.value: 52<br />.color_mod: testing<br />.color_mod: testing"],"type":"scatter","mode":"lines","line":{"width":1.88976377952756,"color":"rgba(227,26,28,1)","dash":"solid"},"hoveron":"points","name":"testing","legendgroup":"testing","showlegend":true,"xaxis":"x","yaxis":"y","hoverinfo":"text","frame":null}],"layout":{"margin":{"t":57.400304414003,"r":7.30593607305936,"b":27.5190258751903,"l":22.648401826484},"plot_bgcolor":"rgba(255,255,255,1)","paper_bgcolor":"rgba(255,255,255,1)","font":{"color":"rgba(44,62,80,1)","family":"","size":14.6118721461187},"title":{"text":"Time Series Cross Validation Plan","font":{"color":"rgba(44,62,80,1)","family":"","size":17.5342465753425},"x":0,"xref":"paper"},"xaxis":{"domain":[0,1],"automargin":true,"type":"date","autorange":true,"range":["1987-05-26","2022-09-09"],"tickmode":"auto","ticktext":["1990","2000","2010","2020"],"tickvals":[7305,10957,14610,18262],"categoryorder":"array","categoryarray":["1990","2000","2010","2020"],"nticks":null,"ticks":"outside","tickcolor":"rgba(204,204,204,1)","ticklen":3.65296803652968,"tickwidth":0.22139200221392,"showticklabels":true,"tickfont":{"color":"rgba(44,62,80,1)","family":"","size":11.689497716895},"tickangle":-0,"showline":false,"linecolor":null,"linewidth":0,"showgrid":true,"gridcolor":"rgba(204,204,204,1)","gridwidth":0.22139200221392,"zeroline":false,"anchor":"y","title":"","hoverformat":".2f"},"yaxis":{"domain":[0,1],"automargin":true,"type":"linear","autorange":true,"range":[32.7,61.3],"tickmode":"auto","ticktext":["40","50","60"],"tickvals":[40,50,60],"categoryorder":"array","categoryarray":["40","50","60"],"nticks":null,"ticks":"outside","tickcolor":"rgba(204,204,204,1)","ticklen":3.65296803652968,"tickwidth":0.22139200221392,"showticklabels":true,"tickfont":{"color":"rgba(44,62,80,1)","family":"","size":11.689497716895},"tickangle":-0,"showline":false,"linecolor":null,"linewidth":0,"showgrid":true,"gridcolor":"rgba(204,204,204,1)","gridwidth":0.22139200221392,"zeroline":false,"anchor":"x","title":"","hoverformat":".2f"},"shapes":[{"type":"rect","fillcolor":"transparent","line":{"color":"rgba(44,62,80,1)","width":0.33208800332088,"linetype":"solid"},"yref":"paper","xref":"paper","x0":0,"x1":1,"y0":0,"y1":1},{"type":"rect","fillcolor":"rgba(44,62,80,1)","line":{"color":"rgba(44,62,80,1)","width":0.66417600664176,"linetype":"solid"},"yref":"paper","xref":"paper","x0":0,"x1":1,"y0":0,"y1":24.9730178497302,"yanchor":1,"ysizemode":"pixel"}],"annotations":[{"text":"Slice1","x":0.5,"y":1,"showarrow":false,"ax":0,"ay":0,"font":{"color":"rgba(255,255,255,1)","family":"","size":11.689497716895},"xref":"paper","yref":"paper","textangle":-0,"xanchor":"center","yanchor":"bottom"}],"showlegend":true,"legend":{"bgcolor":"rgba(255,255,255,1)","bordercolor":"transparent","borderwidth":1.88976377952756,"font":{"color":"rgba(44,62,80,1)","family":"","size":11.689497716895},"title":{"text":"Legend","font":{"color":"rgba(44,62,80,1)","family":"","size":14.6118721461187}}},"hovermode":"closest","barmode":"relative"},"config":{"doubleClick":"reset","modeBarButtonsToAdd":["hoverclosest","hovercompare"],"showSendToCloud":false},"source":"A","attrs":{"3c2017f16d61":{"x":{},"y":{},"colour":{},"type":"scatter"}},"cur_data":"3c2017f16d61","visdat":{"3c2017f16d61":["function (y) ","x"]},"highlight":{"on":"plotly_click","persistent":false,"dynamic":false,"selectize":false,"opacityDim":0.2,"selected":{"opacity":1},"debounce":0},"shinyEvents":["plotly_hover","plotly_click","plotly_selected","plotly_relayout","plotly_brushed","plotly_brushing","plotly_clickannotation","plotly_doubleclick","plotly_deselect","plotly_afterplot","plotly_sunburstclick"],"base_url":"https://plot.ly"},"evals":[],"jsHooks":[]}</script> --- ### Receta 🌮 Se crea una receta de **preprocesamiento**, incluye la fórmula a estimar y un paso adicional que añade variables en función de la fecha. ```r receta <- recipe(value ~ date, data = training(splits)) %>% step_timeseries_signature(date) %>% step_rm(contains("iso"), contains("minute"), contains("hour"), contains("am.pm"), contains("xts"), contains("second"), date_index.num, date_wday, date_month) ``` <div id="xonzjlfhnm" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #xonzjlfhnm .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #xonzjlfhnm .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #xonzjlfhnm .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #xonzjlfhnm .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 0; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #xonzjlfhnm .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xonzjlfhnm .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #xonzjlfhnm .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #xonzjlfhnm .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #xonzjlfhnm .gt_column_spanner_outer:first-child { padding-left: 0; } #xonzjlfhnm .gt_column_spanner_outer:last-child { padding-right: 0; } #xonzjlfhnm .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #xonzjlfhnm .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; } #xonzjlfhnm .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #xonzjlfhnm .gt_from_md > :first-child { margin-top: 0; } #xonzjlfhnm .gt_from_md > :last-child { margin-bottom: 0; } #xonzjlfhnm .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #xonzjlfhnm .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #xonzjlfhnm .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #xonzjlfhnm .gt_row_group_first td { border-top-width: 2px; } #xonzjlfhnm .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #xonzjlfhnm .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #xonzjlfhnm .gt_first_summary_row.thick { border-top-width: 2px; } #xonzjlfhnm .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xonzjlfhnm .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #xonzjlfhnm .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #xonzjlfhnm .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #xonzjlfhnm .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xonzjlfhnm .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #xonzjlfhnm .gt_footnote { margin: 0px; font-size: 90%; padding-left: 4px; padding-right: 4px; padding-left: 5px; padding-right: 5px; } #xonzjlfhnm .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #xonzjlfhnm .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #xonzjlfhnm .gt_left { text-align: left; } #xonzjlfhnm .gt_center { text-align: center; } #xonzjlfhnm .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #xonzjlfhnm .gt_font_normal { font-weight: normal; } #xonzjlfhnm .gt_font_bold { font-weight: bold; } #xonzjlfhnm .gt_font_italic { font-style: italic; } #xonzjlfhnm .gt_super { font-size: 65%; } #xonzjlfhnm .gt_footnote_marks { font-style: italic; font-weight: normal; font-size: 75%; vertical-align: 0.4em; } #xonzjlfhnm .gt_asterisk { font-size: 100%; vertical-align: 0; } #xonzjlfhnm .gt_indent_1 { text-indent: 5px; } #xonzjlfhnm .gt_indent_2 { text-indent: 10px; } #xonzjlfhnm .gt_indent_3 { text-indent: 15px; } #xonzjlfhnm .gt_indent_4 { text-indent: 20px; } #xonzjlfhnm .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table"> <thead class="gt_col_headings"> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">value</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_year</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_half</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_quarter</th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col">date_month.lbl</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_day</th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col">date_wday.lbl</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_mday</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_qday</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_yday</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_mweek</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_week</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_week2</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_week3</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_week4</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1" scope="col">date_mday7</th> </tr> </thead> <tbody class="gt_table_body"> <tr><td class="gt_row gt_right">1989-01-01</td> <td class="gt_row gt_right">51</td> <td class="gt_row gt_right">1989</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_center">January</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_center">Sunday</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">5</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">1</td></tr> <tr><td class="gt_row gt_right">1989-02-01</td> <td class="gt_row gt_right">52</td> <td class="gt_row gt_right">1989</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_center">February</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_center">Wednesday</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">32</td> <td class="gt_row gt_right">32</td> <td class="gt_row gt_right">5</td> <td class="gt_row gt_right">5</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">2</td> <td class="gt_row gt_right">1</td> <td class="gt_row gt_right">1</td></tr> </tbody> </table> </div> --- ### Modelos 🚀 Definición y ajuste de modelos sobre train ```r # Modelo: Auto-ARIMA m_autoarima <- arima_reg() %>% set_engine('auto_arima') %>% fit(value~date, data=training(splits)) # Modelo: exponential smoothing m_exp_smoothing <- exp_smoothing() %>% set_engine('ets') %>% fit(value~date, data=training(splits)) # Workflow: prophet boosted m_prophet_boost <- workflow() %>% add_recipe(receta) %>% add_model( prophet_boost(mode='regression') %>% set_engine("prophet_xgboost") ) %>% fit(data = training(splits)) ``` --- ### Modeltimetable El objeto central del ecosistema #modeltime 📦 es el **modeltime_table**, el cual incluye todos los modelos entrenados para realizar comparaciones. ```r modelos <- modeltime_table(m_autoarima, m_exp_smoothing, m_prophet_boost ) ``` -- <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":[".model_id"],"name":[1],"type":["int"],"align":["right"]},{"label":[".model"],"name":[2],"type":["list"],"align":["right"]},{"label":[".model_desc"],"name":[3],"type":["chr"],"align":["left"]}],"data":[{"1":"1","2":"<S3: _auto_arima_fit_impl>","3":"ARIMA(0,1,1)(0,1,1)[12]"},{"1":"2","2":"<S3: _ets_fit_impl>","3":"ETS(A,N,A)"},{"1":"3","2":"<S3: workflow>","3":"PROPHET W/ XGBOOST ERRORS"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[6],"max":[6]},"pages":{}}} </script> </div> --- ### Calibración de modelos 🔧 Se verifica el **rendimiento** de los modelos sobre la partición de test. ```r calibration_table <- modelos %>% modeltime_calibrate(new_data = testing(splits)) ``` -- * Verificación de métricas 🎯 ```r calibration_table %>% modeltime_accuracy() ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":[".model_id"],"name":[1],"type":["int"],"align":["right"]},{"label":[".model_desc"],"name":[2],"type":["chr"],"align":["left"]},{"label":["mae"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["mape"],"name":[4],"type":["dbl"],"align":["right"]},{"label":["mase"],"name":[5],"type":["dbl"],"align":["right"]},{"label":["smape"],"name":[6],"type":["dbl"],"align":["right"]},{"label":["rmse"],"name":[7],"type":["dbl"],"align":["right"]},{"label":["rsq"],"name":[8],"type":["dbl"],"align":["right"]}],"data":[{"1":"1","2":"ARIMA(0,1,1)(0,1,1)[12]","3":"3.256071","4":"6.929972","5":"0.9532983","6":"6.601998","7":"3.917026","8":"0.6656222"},{"1":"2","2":"ETS(A,N,A)","3":"2.062559","4":"4.276337","5":"0.6038670","6":"4.249388","7":"2.628818","8":"0.6433330"},{"1":"3","2":"PROPHET W/ XGBOOST ERRORS","3":"3.132737","4":"6.664286","5":"0.9171891","6":"6.379083","7":"3.720455","8":"0.6363483"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[6],"max":[6]},"pages":{}}} </script> </div> --- * Forecasting 🔬 Se realiza la **proyección** sobre los datos de testing para luego visualizarla. ```r forecast_series <- calibration_table %>% modeltime_forecast( new_data = testing(splits), actual_data = data_hawaii) ``` --- ### Verificación visual ```r forecast_series %>% plot_modeltime_forecast( .legend_max_width = 30, .interactive = FALSE, .conf_interval_alpha = 0.2 ) ``` 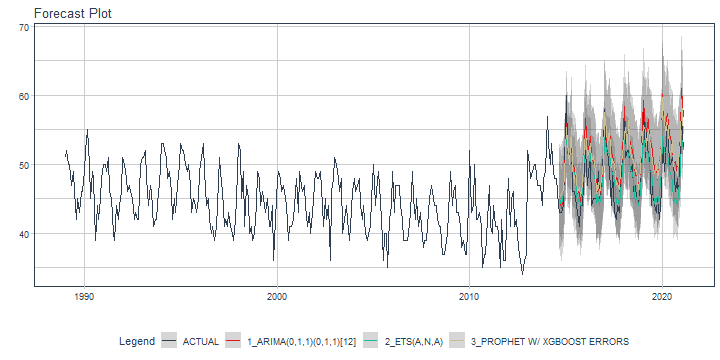<!-- --> --- ### Selección y reajuste de modelos Se seleccionan 2 modelos y luego se reajustan ambos modelos en todos los datos (train + test) ```r refit_tbl <- calibration_table %>% filter(.model_id %in% c(1,2)) %>% modeltime_refit(data = data_hawaii) ``` -- ## Proyección 🔮 ```r forecast_final <- refit_tbl %>% modeltime_forecast( actual_data = data_hawaii, h='2 years' ) ``` --- ### Visualización de la proyección a 2 años ```r forecast_final %>% plot_modeltime_forecast( .legend_max_width = 30, .interactive = FALSE, .conf_interval_alpha = 0.2 ) ``` 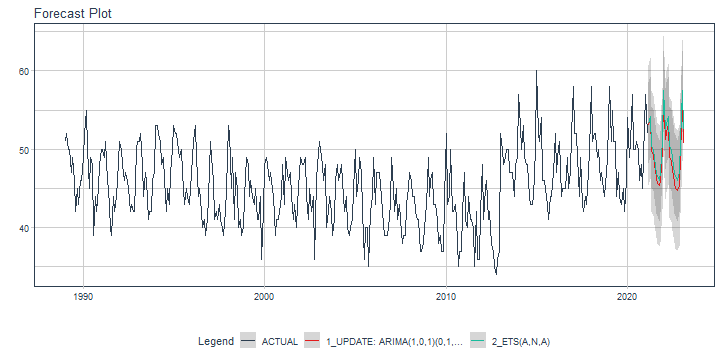<!-- --> --- # Múltiples modelos sobre múltiples series (no panel) <img src="diagrama_multifit.png" width="5081" style="display: block; margin: auto;" /> --- ## Datos 📊 ```r nest_data <- data %>% nest(nested_column = -state) ``` <div id="htmlwidget-a99c3fa2ebc37f2c182a" class="reactable html-widget" style="width:auto;height:auto;"></div> <script type="application/json" data-for="htmlwidget-a99c3fa2ebc37f2c182a">{"x":{"tag":{"name":"Reactable","attribs":{"data":{"state":["Hawaii","Maine","Nevada","West Virginia"],"nested_column":[{"date":["1989-01-01","1989-02-01","1989-03-01","1989-04-01","1989-05-01","1989-06-01","1989-07-01","1989-08-01","1989-09-01","1989-10-01","1989-11-01","1989-12-01","1990-01-01","1990-02-01","1990-03-01","1990-04-01","1990-05-01","1990-06-01","1990-07-01","1990-08-01","1990-09-01","1990-10-01","1990-11-01","1990-12-01","1991-01-01","1991-02-01","1991-03-01","1991-04-01","1991-05-01","1991-06-01","1991-07-01","1991-08-01","1991-09-01","1991-10-01","1991-11-01","1991-12-01","1992-01-01","1992-02-01","1992-03-01","1992-04-01","1992-05-01","1992-06-01","1992-07-01","1992-08-01","1992-09-01","1992-10-01","1992-11-01","1992-12-01","1993-01-01","1993-02-01","1993-03-01","1993-04-01","1993-05-01","1993-06-01","1993-07-01","1993-08-01","1993-09-01","1993-10-01","1993-11-01","1993-12-01","1994-01-01","1994-02-01","1994-03-01","1994-04-01","1994-05-01","1994-06-01","1994-07-01","1994-08-01","1994-09-01","1994-10-01","1994-11-01","1994-12-01","1995-01-01","1995-02-01","1995-03-01","1995-04-01","1995-05-01","1995-06-01","1995-07-01","1995-08-01","1995-09-01","1995-10-01","1995-11-01","1995-12-01","1996-01-01","1996-02-01","1996-03-01","1996-04-01","1996-05-01","1996-06-01","1996-07-01","1996-08-01","1996-09-01","1996-10-01","1996-11-01","1996-12-01","1997-01-01","1997-02-01","1997-03-01","1997-04-01","1997-05-01","1997-06-01","1997-07-01","1997-08-01","1997-09-01","1997-10-01","1997-11-01","1997-12-01","1998-01-01","1998-02-01","1998-03-01","1998-04-01","1998-05-01","1998-06-01","1998-07-01","1998-08-01","1998-09-01","1998-10-01","1998-11-01","1998-12-01","1999-01-01","1999-02-01","1999-03-01","1999-04-01","1999-05-01","1999-06-01","1999-07-01","1999-08-01","1999-09-01","1999-10-01","1999-11-01","1999-12-01","2000-01-01","2000-02-01","2000-03-01","2000-04-01","2000-05-01","2000-06-01","2000-07-01","2000-08-01","2000-09-01","2000-10-01","2000-11-01","2000-12-01","2001-01-01","2001-02-01","2001-03-01","2001-04-01","2001-05-01","2001-06-01","2001-07-01","2001-08-01","2001-09-01","2001-10-01","2001-11-01","2001-12-01","2002-01-01","2002-02-01","2002-03-01","2002-04-01","2002-05-01","2002-06-01","2002-07-01","2002-08-01","2002-09-01","2002-10-01","2002-11-01","2002-12-01","2003-01-01","2003-02-01","2003-03-01","2003-04-01","2003-05-01","2003-06-01","2003-07-01","2003-08-01","2003-09-01","2003-10-01","2003-11-01","2003-12-01","2004-01-01","2004-02-01","2004-03-01","2004-04-01","2004-05-01","2004-06-01","2004-07-01","2004-08-01","2004-09-01","2004-10-01","2004-11-01","2004-12-01","2005-01-01","2005-02-01","2005-03-01","2005-04-01","2005-05-01","2005-06-01","2005-07-01","2005-08-01","2005-09-01","2005-10-01","2005-11-01","2005-12-01","2006-01-01","2006-02-01","2006-03-01","2006-04-01","2006-05-01","2006-06-01","2006-07-01","2006-08-01","2006-09-01","2006-10-01","2006-11-01","2006-12-01","2007-01-01","2007-02-01","2007-03-01","2007-04-01","2007-05-01","2007-06-01","2007-07-01","2007-08-01","2007-09-01","2007-10-01","2007-11-01","2007-12-01","2008-01-01","2008-02-01","2008-03-01","2008-04-01","2008-05-01","2008-06-01","2008-07-01","2008-08-01","2008-09-01","2008-10-01","2008-11-01","2008-12-01","2009-01-01","2009-02-01","2009-03-01","2009-04-01","2009-05-01","2009-06-01","2009-07-01","2009-08-01","2009-09-01","2009-10-01","2009-11-01","2009-12-01","2010-01-01","2010-02-01","2010-03-01","2010-04-01","2010-05-01","2010-06-01","2010-07-01","2010-08-01","2010-09-01","2010-10-01","2010-11-01","2010-12-01","2011-01-01","2011-02-01","2011-03-01","2011-04-01","2011-05-01","2011-06-01","2011-07-01","2011-08-01","2011-09-01","2011-10-01","2011-11-01","2011-12-01","2012-01-01","2012-02-01","2012-03-01","2012-04-01","2012-05-01","2012-06-01","2012-07-01","2012-08-01","2012-09-01","2012-10-01","2012-11-01","2012-12-01","2013-01-01","2013-02-01","2013-03-01","2013-04-01","2013-05-01","2013-06-01","2013-07-01","2013-08-01","2013-09-01","2013-10-01","2013-11-01","2013-12-01","2014-01-01","2014-02-01","2014-03-01","2014-04-01","2014-05-01","2014-06-01","2014-07-01","2014-08-01","2014-09-01","2014-10-01","2014-11-01","2014-12-01","2015-01-01","2015-02-01","2015-03-01","2015-04-01","2015-05-01","2015-06-01","2015-07-01","2015-08-01","2015-09-01","2015-10-01","2015-11-01","2015-12-01","2016-01-01","2016-02-01","2016-03-01","2016-04-01","2016-05-01","2016-06-01","2016-07-01","2016-08-01","2016-09-01","2016-10-01","2016-11-01","2016-12-01","2017-01-01","2017-02-01","2017-03-01","2017-04-01","2017-05-01","2017-06-01","2017-07-01","2017-08-01","2017-09-01","2017-10-01","2017-11-01","2017-12-01","2018-01-01","2018-02-01","2018-03-01","2018-04-01","2018-05-01","2018-06-01","2018-07-01","2018-08-01","2018-09-01","2018-10-01","2018-11-01","2018-12-01","2019-01-01","2019-02-01","2019-03-01","2019-04-01","2019-05-01","2019-06-01","2019-07-01","2019-08-01","2019-09-01","2019-10-01","2019-11-01","2019-12-01","2020-01-01","2020-02-01","2020-03-01","2020-04-01","2020-05-01","2020-06-01","2020-07-01","2020-08-01","2020-09-01","2020-10-01","2020-11-01","2020-12-01","2021-01-01","2021-02-01"],"value":[51,52,50,50,47,49,46,42,45,43,46,46,49,52,55,50,45,49,48,39,44,42,45,48,50,50,49,51,46,45,40,39,44,42,44,46,51,50,48,46,47,46,45,42,43,42,42,50,51,51,52,48,44,47,46,41,42,42,46,47,53,53,52,51,48,49,46,42,45,43,47,50,53,52,52,50,49,50,47,43,45,44,43,45,49,51,53,49,44,45,42,40,41,39,41,44,51,49,46,41,42,41,43,41,40,39,42,45,53,52,45,49,41,47,45,40,41,39,40,44,49,48,44,46,44,43,45,41,41,44,36,42,48,49,48,46,47,45,44,39,41,41,42,44,48,43,49,47,46,47,44,41,43,40,43,47,49,48,48,49,44,41,45,42,44,36,46,48,51,50,48,46,48,40,42,44,42,39,41,46,48,46,47,48,44,42,44,40,39,40,41,45,50,44,46,49,47,42,36,40,40,35,42,44,49,43,47,47,47,44,42,39,39,39,40,43,49,45,42,45,41,43,41,38,39,39,43,45,47,46,44,44,42,41,41,37,37,38,40,43,49,44,46,47,43,43,41,38,39,37,37,44,52,43,44,50,42,42,43,41,35,37,37,42,47,41,40,44,41,41,40,35,42,36,36,42,48,41,45,46,41,42,38,37,35,34,36,37,52,50,48,49,50,50,47,47,47,44,48,49,57,53,50,53,49,48,48,44,43,43,44,50,60,52,51,54,46,46,45,43,41,44,44,47,52,47,49,51,44,45,45,45,49,45,47,52,58,52,52,49,44,49,43,42,44,43,47,50,58,51,52,52,49,50,46,47,45,44,47,49,58,51,55,51,51,44,47,44,43,45,42,46,54,49,51,57,50,50,51,50,46,48,45,53,57,52]},{"date":["1989-01-01","1989-02-01","1989-03-01","1989-04-01","1989-05-01","1989-06-01","1989-07-01","1989-08-01","1989-09-01","1989-10-01","1989-11-01","1989-12-01","1990-01-01","1990-02-01","1990-03-01","1990-04-01","1990-05-01","1990-06-01","1990-07-01","1990-08-01","1990-09-01","1990-10-01","1990-11-01","1990-12-01","1991-01-01","1991-02-01","1991-03-01","1991-04-01","1991-05-01","1991-06-01","1991-07-01","1991-08-01","1991-09-01","1991-10-01","1991-11-01","1991-12-01","1992-01-01","1992-02-01","1992-03-01","1992-04-01","1992-05-01","1992-06-01","1992-07-01","1992-08-01","1992-09-01","1992-10-01","1992-11-01","1992-12-01","1993-01-01","1993-02-01","1993-03-01","1993-04-01","1993-05-01","1993-06-01","1993-07-01","1993-08-01","1993-09-01","1993-10-01","1993-11-01","1993-12-01","1994-01-01","1994-02-01","1994-03-01","1994-04-01","1994-05-01","1994-06-01","1994-07-01","1994-08-01","1994-09-01","1994-10-01","1994-11-01","1994-12-01","1995-01-01","1995-02-01","1995-03-01","1995-04-01","1995-05-01","1995-06-01","1995-07-01","1995-08-01","1995-09-01","1995-10-01","1995-11-01","1995-12-01","1996-01-01","1996-02-01","1996-03-01","1996-04-01","1996-05-01","1996-06-01","1996-07-01","1996-08-01","1996-09-01","1996-10-01","1996-11-01","1996-12-01","1997-01-01","1997-02-01","1997-03-01","1997-04-01","1997-05-01","1997-06-01","1997-07-01","1997-08-01","1997-09-01","1997-10-01","1997-11-01","1997-12-01","1998-01-01","1998-02-01","1998-03-01","1998-04-01","1998-05-01","1998-06-01","1998-07-01","1998-08-01","1998-09-01","1998-10-01","1998-11-01","1998-12-01","1999-01-01","1999-02-01","1999-03-01","1999-04-01","1999-05-01","1999-06-01","1999-07-01","1999-08-01","1999-09-01","1999-10-01","1999-11-01","1999-12-01","2000-01-01","2000-02-01","2000-03-01","2000-04-01","2000-05-01","2000-06-01","2000-07-01","2000-08-01","2000-09-01","2000-10-01","2000-11-01","2000-12-01","2001-01-01","2001-02-01","2001-03-01","2001-04-01","2001-05-01","2001-06-01","2001-07-01","2001-08-01","2001-09-01","2001-10-01","2001-11-01","2001-12-01","2002-01-01","2002-02-01","2002-03-01","2002-04-01","2002-05-01","2002-06-01","2002-07-01","2002-08-01","2002-09-01","2002-10-01","2002-11-01","2002-12-01","2003-01-01","2003-02-01","2003-03-01","2003-04-01","2003-05-01","2003-06-01","2003-07-01","2003-08-01","2003-09-01","2003-10-01","2003-11-01","2003-12-01","2004-01-01","2004-02-01","2004-03-01","2004-04-01","2004-05-01","2004-06-01","2004-07-01","2004-08-01","2004-09-01","2004-10-01","2004-11-01","2004-12-01","2005-01-01","2005-02-01","2005-03-01","2005-04-01","2005-05-01","2005-06-01","2005-07-01","2005-08-01","2005-09-01","2005-10-01","2005-11-01","2005-12-01","2006-01-01","2006-02-01","2006-03-01","2006-04-01","2006-05-01","2006-06-01","2006-07-01","2006-08-01","2006-09-01","2006-10-01","2006-11-01","2006-12-01","2007-01-01","2007-02-01","2007-03-01","2007-04-01","2007-05-01","2007-06-01","2007-07-01","2007-08-01","2007-09-01","2007-10-01","2007-11-01","2007-12-01","2008-01-01","2008-02-01","2008-03-01","2008-04-01","2008-05-01","2008-06-01","2008-07-01","2008-08-01","2008-09-01","2008-10-01","2008-11-01","2008-12-01","2009-01-01","2009-02-01","2009-03-01","2009-04-01","2009-05-01","2009-06-01","2009-07-01","2009-08-01","2009-09-01","2009-10-01","2009-11-01","2009-12-01","2010-01-01","2010-02-01","2010-03-01","2010-04-01","2010-05-01","2010-06-01","2010-07-01","2010-08-01","2010-09-01","2010-10-01","2010-11-01","2010-12-01","2011-01-01","2011-02-01","2011-03-01","2011-04-01","2011-05-01","2011-06-01","2011-07-01","2011-08-01","2011-09-01","2011-10-01","2011-11-01","2011-12-01","2012-01-01","2012-02-01","2012-03-01","2012-04-01","2012-05-01","2012-06-01","2012-07-01","2012-08-01","2012-09-01","2012-10-01","2012-11-01","2012-12-01","2013-01-01","2013-02-01","2013-03-01","2013-04-01","2013-05-01","2013-06-01","2013-07-01","2013-08-01","2013-09-01","2013-10-01","2013-11-01","2013-12-01","2014-01-01","2014-02-01","2014-03-01","2014-04-01","2014-05-01","2014-06-01","2014-07-01","2014-08-01","2014-09-01","2014-10-01","2014-11-01","2014-12-01","2015-01-01","2015-02-01","2015-03-01","2015-04-01","2015-05-01","2015-06-01","2015-07-01","2015-08-01","2015-09-01","2015-10-01","2015-11-01","2015-12-01","2016-01-01","2016-02-01","2016-03-01","2016-04-01","2016-05-01","2016-06-01","2016-07-01","2016-08-01","2016-09-01","2016-10-01","2016-11-01","2016-12-01","2017-01-01","2017-02-01","2017-03-01","2017-04-01","2017-05-01","2017-06-01","2017-07-01","2017-08-01","2017-09-01","2017-10-01","2017-11-01","2017-12-01","2018-01-01","2018-02-01","2018-03-01","2018-04-01","2018-05-01","2018-06-01","2018-07-01","2018-08-01","2018-09-01","2018-10-01","2018-11-01","2018-12-01","2019-01-01","2019-02-01","2019-03-01","2019-04-01","2019-05-01","2019-06-01","2019-07-01","2019-08-01","2019-09-01","2019-10-01","2019-11-01","2019-12-01","2020-01-01","2020-02-01","2020-03-01","2020-04-01","2020-05-01","2020-06-01","2020-07-01","2020-08-01","2020-09-01","2020-10-01","2020-11-01","2020-12-01","2021-01-01","2021-02-01"],"value":[92,84,92,66,49,27,12,19,21,35,46,95,109,86,82,67,48,30,20,19,22,27,56,83,106,105,94,76,46,32,24,19,26,36,56,102,128,139,122,96,66,37,24,22,17,41,70,111,144,153,114,71,38,30,22,22,27,62,88,129,171,135,116,69,49,32,23,22,30,51,78,117,130,139,112,81,48,28,24,24,31,48,97,151,159,143,137,81,49,29,25,23,28,67,105,120,166,133,142,85,56,34,21,26,30,66,107,142,152,127,120,71,45,31,22,25,27,62,95,132,165,133,131,76,40,26,21,25,27,69,93,151,202,122,123,89,49,31,27,26,32,63,96,176,175,154,143,91,38,22,25,25,32,54,61,132,150,147,143,94,52,32,27,28,28,70,110,175,215,191,173,114,60,31,28,29,30,63,105,172,236,181,158,102,47,32,28,28,32,62,104,179,208,174,171,86,63,30,28,30,28,59,102,170,153,166,142,87,52,18,30,27,30,60,84,137,181,207,162,110,51,33,36,19,30,46,106,186,179,177,167,88,49,25,25,29,33,61,108,160,242,229,191,127,66,47,36,26,29,51,100,142,219,186,144,107,62,35,27,28,31,64,127,203,269,234,194,134,71,45,33,25,37,62,115,190,255,221,158,103,67,53,34,32,41,80,180,264,339,293,240,165,80,48,37,34,43,78,195,338,421,361,363,206,112,55,41,41,54,105,249,350,526,529,404,224,95,71,49,48,48,145,246,315,436,388,330,255,136,60,50,44,56,133,229,449,447,395,426,235,135,76,52,54,58,85,264,520,592,411,394,277,116,75,50,55,61,171,385,492,566,511,423,260,167,83,49,49,64,141,354,467,498,461,371,283,164,72,54,53,67,121.94025974026,272,424,562,501]},{"date":["1989-01-01","1989-02-01","1989-03-01","1989-04-01","1989-05-01","1989-06-01","1989-07-01","1989-08-01","1989-09-01","1989-10-01","1989-11-01","1989-12-01","1990-01-01","1990-02-01","1990-03-01","1990-04-01","1990-05-01","1990-06-01","1990-07-01","1990-08-01","1990-09-01","1990-10-01","1990-11-01","1990-12-01","1991-01-01","1991-02-01","1991-03-01","1991-04-01","1991-05-01","1991-06-01","1991-07-01","1991-08-01","1991-09-01","1991-10-01","1991-11-01","1991-12-01","1992-01-01","1992-02-01","1992-03-01","1992-04-01","1992-05-01","1992-06-01","1992-07-01","1992-08-01","1992-09-01","1992-10-01","1992-11-01","1992-12-01","1993-01-01","1993-02-01","1993-03-01","1993-04-01","1993-05-01","1993-06-01","1993-07-01","1993-08-01","1993-09-01","1993-10-01","1993-11-01","1993-12-01","1994-01-01","1994-02-01","1994-03-01","1994-04-01","1994-05-01","1994-06-01","1994-07-01","1994-08-01","1994-09-01","1994-10-01","1994-11-01","1994-12-01","1995-01-01","1995-02-01","1995-03-01","1995-04-01","1995-05-01","1995-06-01","1995-07-01","1995-08-01","1995-09-01","1995-10-01","1995-11-01","1995-12-01","1996-01-01","1996-02-01","1996-03-01","1996-04-01","1996-05-01","1996-06-01","1996-07-01","1996-08-01","1996-09-01","1996-10-01","1996-11-01","1996-12-01","1997-01-01","1997-02-01","1997-03-01","1997-04-01","1997-05-01","1997-06-01","1997-07-01","1997-08-01","1997-09-01","1997-10-01","1997-11-01","1997-12-01","1998-01-01","1998-02-01","1998-03-01","1998-04-01","1998-05-01","1998-06-01","1998-07-01","1998-08-01","1998-09-01","1998-10-01","1998-11-01","1998-12-01","1999-01-01","1999-02-01","1999-03-01","1999-04-01","1999-05-01","1999-06-01","1999-07-01","1999-08-01","1999-09-01","1999-10-01","1999-11-01","1999-12-01","2000-01-01","2000-02-01","2000-03-01","2000-04-01","2000-05-01","2000-06-01","2000-07-01","2000-08-01","2000-09-01","2000-10-01","2000-11-01","2000-12-01","2001-01-01","2001-02-01","2001-03-01","2001-04-01","2001-05-01","2001-06-01","2001-07-01","2001-08-01","2001-09-01","2001-10-01","2001-11-01","2001-12-01","2002-01-01","2002-02-01","2002-03-01","2002-04-01","2002-05-01","2002-06-01","2002-07-01","2002-08-01","2002-09-01","2002-10-01","2002-11-01","2002-12-01","2003-01-01","2003-02-01","2003-03-01","2003-04-01","2003-05-01","2003-06-01","2003-07-01","2003-08-01","2003-09-01","2003-10-01","2003-11-01","2003-12-01","2004-01-01","2004-02-01","2004-03-01","2004-04-01","2004-05-01","2004-06-01","2004-07-01","2004-08-01","2004-09-01","2004-10-01","2004-11-01","2004-12-01","2005-01-01","2005-02-01","2005-03-01","2005-04-01","2005-05-01","2005-06-01","2005-07-01","2005-08-01","2005-09-01","2005-10-01","2005-11-01","2005-12-01","2006-01-01","2006-02-01","2006-03-01","2006-04-01","2006-05-01","2006-06-01","2006-07-01","2006-08-01","2006-09-01","2006-10-01","2006-11-01","2006-12-01","2007-01-01","2007-02-01","2007-03-01","2007-04-01","2007-05-01","2007-06-01","2007-07-01","2007-08-01","2007-09-01","2007-10-01","2007-11-01","2007-12-01","2008-01-01","2008-02-01","2008-03-01","2008-04-01","2008-05-01","2008-06-01","2008-07-01","2008-08-01","2008-09-01","2008-10-01","2008-11-01","2008-12-01","2009-01-01","2009-02-01","2009-03-01","2009-04-01","2009-05-01","2009-06-01","2009-07-01","2009-08-01","2009-09-01","2009-10-01","2009-11-01","2009-12-01","2010-01-01","2010-02-01","2010-03-01","2010-04-01","2010-05-01","2010-06-01","2010-07-01","2010-08-01","2010-09-01","2010-10-01","2010-11-01","2010-12-01","2011-01-01","2011-02-01","2011-03-01","2011-04-01","2011-05-01","2011-06-01","2011-07-01","2011-08-01","2011-09-01","2011-10-01","2011-11-01","2011-12-01","2012-01-01","2012-02-01","2012-03-01","2012-04-01","2012-05-01","2012-06-01","2012-07-01","2012-08-01","2012-09-01","2012-10-01","2012-11-01","2012-12-01","2013-01-01","2013-02-01","2013-03-01","2013-04-01","2013-05-01","2013-06-01","2013-07-01","2013-08-01","2013-09-01","2013-10-01","2013-11-01","2013-12-01","2014-01-01","2014-02-01","2014-03-01","2014-04-01","2014-05-01","2014-06-01","2014-07-01","2014-08-01","2014-09-01","2014-10-01","2014-11-01","2014-12-01","2015-01-01","2015-02-01","2015-03-01","2015-04-01","2015-05-01","2015-06-01","2015-07-01","2015-08-01","2015-09-01","2015-10-01","2015-11-01","2015-12-01","2016-01-01","2016-02-01","2016-03-01","2016-04-01","2016-05-01","2016-06-01","2016-07-01","2016-08-01","2016-09-01","2016-10-01","2016-11-01","2016-12-01","2017-01-01","2017-02-01","2017-03-01","2017-04-01","2017-05-01","2017-06-01","2017-07-01","2017-08-01","2017-09-01","2017-10-01","2017-11-01","2017-12-01","2018-01-01","2018-02-01","2018-03-01","2018-04-01","2018-05-01","2018-06-01","2018-07-01","2018-08-01","2018-09-01","2018-10-01","2018-11-01","2018-12-01","2019-01-01","2019-02-01","2019-03-01","2019-04-01","2019-05-01","2019-06-01","2019-07-01","2019-08-01","2019-09-01","2019-10-01","2019-11-01","2019-12-01","2020-01-01","2020-02-01","2020-03-01","2020-04-01","2020-05-01","2020-06-01","2020-07-01","2020-08-01","2020-09-01","2020-10-01","2020-11-01","2020-12-01","2021-01-01","2021-02-01"],"value":[3128,2971,1957,1106,829,748,531,478,555,703,1400,2359,2988,3010,2208,1127,862,775,562,520,521,717,1270,2593,3919,2512,2116,1876,1208,853,622,546,547,680,1315,2941,3525,2611,2094,1394,803,695,671,529,608,727,1226,3302,3892,3157,2715,1503,1087,910,600,612,651,804,1492,3261,3597,3331,2505,1474,1151,883,669,587,632,829,1751,3855,3927,3102,2189,2156,1568,1087,801,655,677,817,1349,2357,3744,3264,2903,1884,1264,1011,779,678,732,894,2069,3386,4490,3843,3187,2027,1401,985,891,781,805,1024,1925,3884,5025,4149,3809,2826,1884,1487,977,813,824,1367,2526,4335,4935,4309,3331,2704,1843,1233,940,921,953,1208,1998,4396,4985,3863,3711,2027,1568,1184,1009,932,1085,1399,3228,4950,5541,5420,3978,2473,1641,1175,1042,996,1034,1245,2188,5877,5871,5596,3726,2405,1753,1296,1033,940,1081,1428,2603,4226,5431,4563,4059,2814,2114,1221,1114,994,1075,1272,2816,5374,6772,5908,4037,2025,1724,1419,1190,1083,1216,1587,3498,6075,6833,5631,3894,3081,2044,1633,1173,1115,1279,1623,2513,5578,6188,5415,5206,3334,1816,1515,1237,1147,1287,1878,2823,6092,8093,5982,4061,2447,1969,1491,1270,1155,1267,1880,2637,5834,8262,6795,4415,2774,1956,1620,1261,1142,1226,1683,2491,5038,7457,5654,4596,2974,1862,1475,1272,1147,1213,1708,2898,6484,7471,5926,4741,3255,2286,1690,1248,1102,1227,1524,3161,5748,7445,5946,4580,2953,2059,1643,1278,1180,1212,1616,3785,6896,7170,5815,4325,2717,1774,1504,1377,1054,1199,1513,3143,5479,9120,6103,4077,2476,1744,1395,1212,1106,1243,2210,3411,7568,6886,5205,3533,2585,1824,1438,1257,1168,1206,1556,3016,5459,7046,4287,3384,2366,1901,1497,1120,1189,1228,1449,4218,7344,8540,5658,3524,2500,1993,1518,1269,1208,1387,1810,2891,6777,8578,6256,4396,2794,2022,1600,1310,1153,1476,2035,2973,6316,6655,6123,5723,2891,2003,1612,1256,1154,1408,2031,4052,6929,8520,8076,6324,3021,2254,1807,1453,1310,1520,2427,3862,7356,8302,6716,5342,3572,2327,1963,1584,1316,1533,2046,4009,7207,8202,6982]},{"date":["1989-01-01","1989-02-01","1989-03-01","1989-04-01","1989-05-01","1989-06-01","1989-07-01","1989-08-01","1989-09-01","1989-10-01","1989-11-01","1989-12-01","1990-01-01","1990-02-01","1990-03-01","1990-04-01","1990-05-01","1990-06-01","1990-07-01","1990-08-01","1990-09-01","1990-10-01","1990-11-01","1990-12-01","1991-01-01","1991-02-01","1991-03-01","1991-04-01","1991-05-01","1991-06-01","1991-07-01","1991-08-01","1991-09-01","1991-10-01","1991-11-01","1991-12-01","1992-01-01","1992-02-01","1992-03-01","1992-04-01","1992-05-01","1992-06-01","1992-07-01","1992-08-01","1992-09-01","1992-10-01","1992-11-01","1992-12-01","1993-01-01","1993-02-01","1993-03-01","1993-04-01","1993-05-01","1993-06-01","1993-07-01","1993-08-01","1993-09-01","1993-10-01","1993-11-01","1993-12-01","1994-01-01","1994-02-01","1994-03-01","1994-04-01","1994-05-01","1994-06-01","1994-07-01","1994-08-01","1994-09-01","1994-10-01","1994-11-01","1994-12-01","1995-01-01","1995-02-01","1995-03-01","1995-04-01","1995-05-01","1995-06-01","1995-07-01","1995-08-01","1995-09-01","1995-10-01","1995-11-01","1995-12-01","1996-01-01","1996-02-01","1996-03-01","1996-04-01","1996-05-01","1996-06-01","1996-07-01","1996-08-01","1996-09-01","1996-10-01","1996-11-01","1996-12-01","1997-01-01","1997-02-01","1997-03-01","1997-04-01","1997-05-01","1997-06-01","1997-07-01","1997-08-01","1997-09-01","1997-10-01","1997-11-01","1997-12-01","1998-01-01","1998-02-01","1998-03-01","1998-04-01","1998-05-01","1998-06-01","1998-07-01","1998-08-01","1998-09-01","1998-10-01","1998-11-01","1998-12-01","1999-01-01","1999-02-01","1999-03-01","1999-04-01","1999-05-01","1999-06-01","1999-07-01","1999-08-01","1999-09-01","1999-10-01","1999-11-01","1999-12-01","2000-01-01","2000-02-01","2000-03-01","2000-04-01","2000-05-01","2000-06-01","2000-07-01","2000-08-01","2000-09-01","2000-10-01","2000-11-01","2000-12-01","2001-01-01","2001-02-01","2001-03-01","2001-04-01","2001-05-01","2001-06-01","2001-07-01","2001-08-01","2001-09-01","2001-10-01","2001-11-01","2001-12-01","2002-01-01","2002-02-01","2002-03-01","2002-04-01","2002-05-01","2002-06-01","2002-07-01","2002-08-01","2002-09-01","2002-10-01","2002-11-01","2002-12-01","2003-01-01","2003-02-01","2003-03-01","2003-04-01","2003-05-01","2003-06-01","2003-07-01","2003-08-01","2003-09-01","2003-10-01","2003-11-01","2003-12-01","2004-01-01","2004-02-01","2004-03-01","2004-04-01","2004-05-01","2004-06-01","2004-07-01","2004-08-01","2004-09-01","2004-10-01","2004-11-01","2004-12-01","2005-01-01","2005-02-01","2005-03-01","2005-04-01","2005-05-01","2005-06-01","2005-07-01","2005-08-01","2005-09-01","2005-10-01","2005-11-01","2005-12-01","2006-01-01","2006-02-01","2006-03-01","2006-04-01","2006-05-01","2006-06-01","2006-07-01","2006-08-01","2006-09-01","2006-10-01","2006-11-01","2006-12-01","2007-01-01","2007-02-01","2007-03-01","2007-04-01","2007-05-01","2007-06-01","2007-07-01","2007-08-01","2007-09-01","2007-10-01","2007-11-01","2007-12-01","2008-01-01","2008-02-01","2008-03-01","2008-04-01","2008-05-01","2008-06-01","2008-07-01","2008-08-01","2008-09-01","2008-10-01","2008-11-01","2008-12-01","2009-01-01","2009-02-01","2009-03-01","2009-04-01","2009-05-01","2009-06-01","2009-07-01","2009-08-01","2009-09-01","2009-10-01","2009-11-01","2009-12-01","2010-01-01","2010-02-01","2010-03-01","2010-04-01","2010-05-01","2010-06-01","2010-07-01","2010-08-01","2010-09-01","2010-10-01","2010-11-01","2010-12-01","2011-01-01","2011-02-01","2011-03-01","2011-04-01","2011-05-01","2011-06-01","2011-07-01","2011-08-01","2011-09-01","2011-10-01","2011-11-01","2011-12-01","2012-01-01","2012-02-01","2012-03-01","2012-04-01","2012-05-01","2012-06-01","2012-07-01","2012-08-01","2012-09-01","2012-10-01","2012-11-01","2012-12-01","2013-01-01","2013-02-01","2013-03-01","2013-04-01","2013-05-01","2013-06-01","2013-07-01","2013-08-01","2013-09-01","2013-10-01","2013-11-01","2013-12-01","2014-01-01","2014-02-01","2014-03-01","2014-04-01","2014-05-01","2014-06-01","2014-07-01","2014-08-01","2014-09-01","2014-10-01","2014-11-01","2014-12-01","2015-01-01","2015-02-01","2015-03-01","2015-04-01","2015-05-01","2015-06-01","2015-07-01","2015-08-01","2015-09-01","2015-10-01","2015-11-01","2015-12-01","2016-01-01","2016-02-01","2016-03-01","2016-04-01","2016-05-01","2016-06-01","2016-07-01","2016-08-01","2016-09-01","2016-10-01","2016-11-01","2016-12-01","2017-01-01","2017-02-01","2017-03-01","2017-04-01","2017-05-01","2017-06-01","2017-07-01","2017-08-01","2017-09-01","2017-10-01","2017-11-01","2017-12-01","2018-01-01","2018-02-01","2018-03-01","2018-04-01","2018-05-01","2018-06-01","2018-07-01","2018-08-01","2018-09-01","2018-10-01","2018-11-01","2018-12-01","2019-01-01","2019-02-01","2019-03-01","2019-04-01","2019-05-01","2019-06-01","2019-07-01","2019-08-01","2019-09-01","2019-10-01","2019-11-01","2019-12-01","2020-01-01","2020-02-01","2020-03-01","2020-04-01","2020-05-01","2020-06-01","2020-07-01","2020-08-01","2020-09-01","2020-10-01","2020-11-01","2020-12-01","2021-01-01","2021-02-01"],"value":[5838,5621,5179,3608,2263,1001,741,695,824,1738,3240,6382,6858,4690,4174,3403,1747,1055,724,696,800,1353,3031,4069,5561,5527,4858,2876,1372,707,629,622,765,1738,3210,4722,6183,6231,4328,4038,2076,1105,683,661,819,1899,3120,4146,5220,5960,5767,3560,1608,962,533,620,740,1818,3347,5072,7397,6344,5136,3281,1841,926,541,625,789,1511,2462,4348,5783,6546,4592,3173,1776,702,574,560,740,1441,3626,5867,6958,6602,5495,3877,1652,817,590,537,696,1609,3391,5166,5908,5572,4273,3386,2223,952,492,598,776,1737,4061,6017,5676,4894,4540,2879,1278,670,513,526,623,1300,2791,3974,6202,4957,5443,2957,1398,657,527,505,681,1339,2541,4195,5832,6279,3818,2491,1898,747,520,535,599,1372,2177,5331,6696,5275,4997,3394,963,442,386,448,752,1527,3089,3970,4915,4814,4528,2641,1609,533,537,448,549,1556,3357,5306,6785,6223,4385,2285,1171,600,477,443,680,1816,2379,4964,6178,6569,4455,2958,1262,484,486,449,491,1065,1959,3974,5162,5469,5157,2534,1660,636,399,396,419,756,2339,4868,4679,4570,4193,2280,1145,618,355,365,500,1159,2623,3597,4242,5694,4898,2305,736,355,363,331,343,889,2568,3806,5137,4779,3983,1765,993,425,364,369,440,1519,3186,4557,5706,4672,3336,1937,755,340,370,348,503,1636,2128,4442,5549,5003,2971,1496,807,399,350,387,436,1239,2796,5587,5695,4049,3538,1740,801,523,363,333,462,1374,2362,3832,4430,4096,1961,1907,458,327,233,379,631,1363,3300,3454,4530,4486,4560,1982,824,467,331,362,549,1356,3198,3870,5909,4950,4484,1972,913,466,360,360,517,1147,3249,3929,5121,5640,4563,1631,668,416,243,337,385,1235,2120,2449,5275,4160,2617,1784,726,371,363,323,360,884,2265,4083,4081,3118,3489,1372,758,325,356,304,485,1014,2610,4473,5522,3644,4242,2439,592,385,330,297,348,1311,3135,4011,5017,3677,3842,1355,654,314,331,343,297,1089,3172,3758,4223,3987,2660,1931,940,669,322,315,500,1072,2085,3904,4954,4689]}]},"columns":[{"accessor":".details","name":"","type":"NULL","sortable":false,"resizable":false,"filterable":false,"searchable":false,"width":45,"align":"center","details":[{"name":"div","attribs":{"style":{"padding":"10px"}},"children":[{"name":"Reactable","attribs":{"data":{"date":["1989-01-01","1989-02-01","1989-03-01","1989-04-01","1989-05-01","1989-06-01","1989-07-01","1989-08-01","1989-09-01","1989-10-01","1989-11-01","1989-12-01","1990-01-01","1990-02-01","1990-03-01","1990-04-01","1990-05-01","1990-06-01","1990-07-01","1990-08-01","1990-09-01","1990-10-01","1990-11-01","1990-12-01","1991-01-01","1991-02-01","1991-03-01","1991-04-01","1991-05-01","1991-06-01","1991-07-01","1991-08-01","1991-09-01","1991-10-01","1991-11-01","1991-12-01","1992-01-01","1992-02-01","1992-03-01","1992-04-01","1992-05-01","1992-06-01","1992-07-01","1992-08-01","1992-09-01","1992-10-01","1992-11-01","1992-12-01","1993-01-01","1993-02-01","1993-03-01","1993-04-01","1993-05-01","1993-06-01","1993-07-01","1993-08-01","1993-09-01","1993-10-01","1993-11-01","1993-12-01","1994-01-01","1994-02-01","1994-03-01","1994-04-01","1994-05-01","1994-06-01","1994-07-01","1994-08-01","1994-09-01","1994-10-01","1994-11-01","1994-12-01","1995-01-01","1995-02-01","1995-03-01","1995-04-01","1995-05-01","1995-06-01","1995-07-01","1995-08-01","1995-09-01","1995-10-01","1995-11-01","1995-12-01","1996-01-01","1996-02-01","1996-03-01","1996-04-01","1996-05-01","1996-06-01","1996-07-01","1996-08-01","1996-09-01","1996-10-01","1996-11-01","1996-12-01","1997-01-01","1997-02-01","1997-03-01","1997-04-01","1997-05-01","1997-06-01","1997-07-01","1997-08-01","1997-09-01","1997-10-01","1997-11-01","1997-12-01","1998-01-01","1998-02-01","1998-03-01","1998-04-01","1998-05-01","1998-06-01","1998-07-01","1998-08-01","1998-09-01","1998-10-01","1998-11-01","1998-12-01","1999-01-01","1999-02-01","1999-03-01","1999-04-01","1999-05-01","1999-06-01","1999-07-01","1999-08-01","1999-09-01","1999-10-01","1999-11-01","1999-12-01","2000-01-01","2000-02-01","2000-03-01","2000-04-01","2000-05-01","2000-06-01","2000-07-01","2000-08-01","2000-09-01","2000-10-01","2000-11-01","2000-12-01","2001-01-01","2001-02-01","2001-03-01","2001-04-01","2001-05-01","2001-06-01","2001-07-01","2001-08-01","2001-09-01","2001-10-01","2001-11-01","2001-12-01","2002-01-01","2002-02-01","2002-03-01","2002-04-01","2002-05-01","2002-06-01","2002-07-01","2002-08-01","2002-09-01","2002-10-01","2002-11-01","2002-12-01","2003-01-01","2003-02-01","2003-03-01","2003-04-01","2003-05-01","2003-06-01","2003-07-01","2003-08-01","2003-09-01","2003-10-01","2003-11-01","2003-12-01","2004-01-01","2004-02-01","2004-03-01","2004-04-01","2004-05-01","2004-06-01","2004-07-01","2004-08-01","2004-09-01","2004-10-01","2004-11-01","2004-12-01","2005-01-01","2005-02-01","2005-03-01","2005-04-01","2005-05-01","2005-06-01","2005-07-01","2005-08-01","2005-09-01","2005-10-01","2005-11-01","2005-12-01","2006-01-01","2006-02-01","2006-03-01","2006-04-01","2006-05-01","2006-06-01","2006-07-01","2006-08-01","2006-09-01","2006-10-01","2006-11-01","2006-12-01","2007-01-01","2007-02-01","2007-03-01","2007-04-01","2007-05-01","2007-06-01","2007-07-01","2007-08-01","2007-09-01","2007-10-01","2007-11-01","2007-12-01","2008-01-01","2008-02-01","2008-03-01","2008-04-01","2008-05-01","2008-06-01","2008-07-01","2008-08-01","2008-09-01","2008-10-01","2008-11-01","2008-12-01","2009-01-01","2009-02-01","2009-03-01","2009-04-01","2009-05-01","2009-06-01","2009-07-01","2009-08-01","2009-09-01","2009-10-01","2009-11-01","2009-12-01","2010-01-01","2010-02-01","2010-03-01","2010-04-01","2010-05-01","2010-06-01","2010-07-01","2010-08-01","2010-09-01","2010-10-01","2010-11-01","2010-12-01","2011-01-01","2011-02-01","2011-03-01","2011-04-01","2011-05-01","2011-06-01","2011-07-01","2011-08-01","2011-09-01","2011-10-01","2011-11-01","2011-12-01","2012-01-01","2012-02-01","2012-03-01","2012-04-01","2012-05-01","2012-06-01","2012-07-01","2012-08-01","2012-09-01","2012-10-01","2012-11-01","2012-12-01","2013-01-01","2013-02-01","2013-03-01","2013-04-01","2013-05-01","2013-06-01","2013-07-01","2013-08-01","2013-09-01","2013-10-01","2013-11-01","2013-12-01","2014-01-01","2014-02-01","2014-03-01","2014-04-01","2014-05-01","2014-06-01","2014-07-01","2014-08-01","2014-09-01","2014-10-01","2014-11-01","2014-12-01","2015-01-01","2015-02-01","2015-03-01","2015-04-01","2015-05-01","2015-06-01","2015-07-01","2015-08-01","2015-09-01","2015-10-01","2015-11-01","2015-12-01","2016-01-01","2016-02-01","2016-03-01","2016-04-01","2016-05-01","2016-06-01","2016-07-01","2016-08-01","2016-09-01","2016-10-01","2016-11-01","2016-12-01","2017-01-01","2017-02-01","2017-03-01","2017-04-01","2017-05-01","2017-06-01","2017-07-01","2017-08-01","2017-09-01","2017-10-01","2017-11-01","2017-12-01","2018-01-01","2018-02-01","2018-03-01","2018-04-01","2018-05-01","2018-06-01","2018-07-01","2018-08-01","2018-09-01","2018-10-01","2018-11-01","2018-12-01","2019-01-01","2019-02-01","2019-03-01","2019-04-01","2019-05-01","2019-06-01","2019-07-01","2019-08-01","2019-09-01","2019-10-01","2019-11-01","2019-12-01","2020-01-01","2020-02-01","2020-03-01","2020-04-01","2020-05-01","2020-06-01","2020-07-01","2020-08-01","2020-09-01","2020-10-01","2020-11-01","2020-12-01","2021-01-01","2021-02-01"],"value":[51,52,50,50,47,49,46,42,45,43,46,46,49,52,55,50,45,49,48,39,44,42,45,48,50,50,49,51,46,45,40,39,44,42,44,46,51,50,48,46,47,46,45,42,43,42,42,50,51,51,52,48,44,47,46,41,42,42,46,47,53,53,52,51,48,49,46,42,45,43,47,50,53,52,52,50,49,50,47,43,45,44,43,45,49,51,53,49,44,45,42,40,41,39,41,44,51,49,46,41,42,41,43,41,40,39,42,45,53,52,45,49,41,47,45,40,41,39,40,44,49,48,44,46,44,43,45,41,41,44,36,42,48,49,48,46,47,45,44,39,41,41,42,44,48,43,49,47,46,47,44,41,43,40,43,47,49,48,48,49,44,41,45,42,44,36,46,48,51,50,48,46,48,40,42,44,42,39,41,46,48,46,47,48,44,42,44,40,39,40,41,45,50,44,46,49,47,42,36,40,40,35,42,44,49,43,47,47,47,44,42,39,39,39,40,43,49,45,42,45,41,43,41,38,39,39,43,45,47,46,44,44,42,41,41,37,37,38,40,43,49,44,46,47,43,43,41,38,39,37,37,44,52,43,44,50,42,42,43,41,35,37,37,42,47,41,40,44,41,41,40,35,42,36,36,42,48,41,45,46,41,42,38,37,35,34,36,37,52,50,48,49,50,50,47,47,47,44,48,49,57,53,50,53,49,48,48,44,43,43,44,50,60,52,51,54,46,46,45,43,41,44,44,47,52,47,49,51,44,45,45,45,49,45,47,52,58,52,52,49,44,49,43,42,44,43,47,50,58,51,52,52,49,50,46,47,45,44,47,49,58,51,55,51,51,44,47,44,43,45,42,46,54,49,51,57,50,50,51,50,46,48,45,53,57,52]},"columns":[{"accessor":"date","name":"date","type":"Date"},{"accessor":"value","name":"value","type":"numeric"}],"defaultPageSize":10,"paginationType":"numbers","showPageInfo":true,"minRows":1,"outlined":true,"dataKey":"c867537963d4500ba71dc5ce086d2592","nested":true},"children":[]}]},{"name":"div","attribs":{"style":{"padding":"10px"}},"children":[{"name":"Reactable","attribs":{"data":{"date":["1989-01-01","1989-02-01","1989-03-01","1989-04-01","1989-05-01","1989-06-01","1989-07-01","1989-08-01","1989-09-01","1989-10-01","1989-11-01","1989-12-01","1990-01-01","1990-02-01","1990-03-01","1990-04-01","1990-05-01","1990-06-01","1990-07-01","1990-08-01","1990-09-01","1990-10-01","1990-11-01","1990-12-01","1991-01-01","1991-02-01","1991-03-01","1991-04-01","1991-05-01","1991-06-01","1991-07-01","1991-08-01","1991-09-01","1991-10-01","1991-11-01","1991-12-01","1992-01-01","1992-02-01","1992-03-01","1992-04-01","1992-05-01","1992-06-01","1992-07-01","1992-08-01","1992-09-01","1992-10-01","1992-11-01","1992-12-01","1993-01-01","1993-02-01","1993-03-01","1993-04-01","1993-05-01","1993-06-01","1993-07-01","1993-08-01","1993-09-01","1993-10-01","1993-11-01","1993-12-01","1994-01-01","1994-02-01","1994-03-01","1994-04-01","1994-05-01","1994-06-01","1994-07-01","1994-08-01","1994-09-01","1994-10-01","1994-11-01","1994-12-01","1995-01-01","1995-02-01","1995-03-01","1995-04-01","1995-05-01","1995-06-01","1995-07-01","1995-08-01","1995-09-01","1995-10-01","1995-11-01","1995-12-01","1996-01-01","1996-02-01","1996-03-01","1996-04-01","1996-05-01","1996-06-01","1996-07-01","1996-08-01","1996-09-01","1996-10-01","1996-11-01","1996-12-01","1997-01-01","1997-02-01","1997-03-01","1997-04-01","1997-05-01","1997-06-01","1997-07-01","1997-08-01","1997-09-01","1997-10-01","1997-11-01","1997-12-01","1998-01-01","1998-02-01","1998-03-01","1998-04-01","1998-05-01","1998-06-01","1998-07-01","1998-08-01","1998-09-01","1998-10-01","1998-11-01","1998-12-01","1999-01-01","1999-02-01","1999-03-01","1999-04-01","1999-05-01","1999-06-01","1999-07-01","1999-08-01","1999-09-01","1999-10-01","1999-11-01","1999-12-01","2000-01-01","2000-02-01","2000-03-01","2000-04-01","2000-05-01","2000-06-01","2000-07-01","2000-08-01","2000-09-01","2000-10-01","2000-11-01","2000-12-01","2001-01-01","2001-02-01","2001-03-01","2001-04-01","2001-05-01","2001-06-01","2001-07-01","2001-08-01","2001-09-01","2001-10-01","2001-11-01","2001-12-01","2002-01-01","2002-02-01","2002-03-01","2002-04-01","2002-05-01","2002-06-01","2002-07-01","2002-08-01","2002-09-01","2002-10-01","2002-11-01","2002-12-01","2003-01-01","2003-02-01","2003-03-01","2003-04-01","2003-05-01","2003-06-01","2003-07-01","2003-08-01","2003-09-01","2003-10-01","2003-11-01","2003-12-01","2004-01-01","2004-02-01","2004-03-01","2004-04-01","2004-05-01","2004-06-01","2004-07-01","2004-08-01","2004-09-01","2004-10-01","2004-11-01","2004-12-01","2005-01-01","2005-02-01","2005-03-01","2005-04-01","2005-05-01","2005-06-01","2005-07-01","2005-08-01","2005-09-01","2005-10-01","2005-11-01","2005-12-01","2006-01-01","2006-02-01","2006-03-01","2006-04-01","2006-05-01","2006-06-01","2006-07-01","2006-08-01","2006-09-01","2006-10-01","2006-11-01","2006-12-01","2007-01-01","2007-02-01","2007-03-01","2007-04-01","2007-05-01","2007-06-01","2007-07-01","2007-08-01","2007-09-01","2007-10-01","2007-11-01","2007-12-01","2008-01-01","2008-02-01","2008-03-01","2008-04-01","2008-05-01","2008-06-01","2008-07-01","2008-08-01","2008-09-01","2008-10-01","2008-11-01","2008-12-01","2009-01-01","2009-02-01","2009-03-01","2009-04-01","2009-05-01","2009-06-01","2009-07-01","2009-08-01","2009-09-01","2009-10-01","2009-11-01","2009-12-01","2010-01-01","2010-02-01","2010-03-01","2010-04-01","2010-05-01","2010-06-01","2010-07-01","2010-08-01","2010-09-01","2010-10-01","2010-11-01","2010-12-01","2011-01-01","2011-02-01","2011-03-01","2011-04-01","2011-05-01","2011-06-01","2011-07-01","2011-08-01","2011-09-01","2011-10-01","2011-11-01","2011-12-01","2012-01-01","2012-02-01","2012-03-01","2012-04-01","2012-05-01","2012-06-01","2012-07-01","2012-08-01","2012-09-01","2012-10-01","2012-11-01","2012-12-01","2013-01-01","2013-02-01","2013-03-01","2013-04-01","2013-05-01","2013-06-01","2013-07-01","2013-08-01","2013-09-01","2013-10-01","2013-11-01","2013-12-01","2014-01-01","2014-02-01","2014-03-01","2014-04-01","2014-05-01","2014-06-01","2014-07-01","2014-08-01","2014-09-01","2014-10-01","2014-11-01","2014-12-01","2015-01-01","2015-02-01","2015-03-01","2015-04-01","2015-05-01","2015-06-01","2015-07-01","2015-08-01","2015-09-01","2015-10-01","2015-11-01","2015-12-01","2016-01-01","2016-02-01","2016-03-01","2016-04-01","2016-05-01","2016-06-01","2016-07-01","2016-08-01","2016-09-01","2016-10-01","2016-11-01","2016-12-01","2017-01-01","2017-02-01","2017-03-01","2017-04-01","2017-05-01","2017-06-01","2017-07-01","2017-08-01","2017-09-01","2017-10-01","2017-11-01","2017-12-01","2018-01-01","2018-02-01","2018-03-01","2018-04-01","2018-05-01","2018-06-01","2018-07-01","2018-08-01","2018-09-01","2018-10-01","2018-11-01","2018-12-01","2019-01-01","2019-02-01","2019-03-01","2019-04-01","2019-05-01","2019-06-01","2019-07-01","2019-08-01","2019-09-01","2019-10-01","2019-11-01","2019-12-01","2020-01-01","2020-02-01","2020-03-01","2020-04-01","2020-05-01","2020-06-01","2020-07-01","2020-08-01","2020-09-01","2020-10-01","2020-11-01","2020-12-01","2021-01-01","2021-02-01"],"value":[92,84,92,66,49,27,12,19,21,35,46,95,109,86,82,67,48,30,20,19,22,27,56,83,106,105,94,76,46,32,24,19,26,36,56,102,128,139,122,96,66,37,24,22,17,41,70,111,144,153,114,71,38,30,22,22,27,62,88,129,171,135,116,69,49,32,23,22,30,51,78,117,130,139,112,81,48,28,24,24,31,48,97,151,159,143,137,81,49,29,25,23,28,67,105,120,166,133,142,85,56,34,21,26,30,66,107,142,152,127,120,71,45,31,22,25,27,62,95,132,165,133,131,76,40,26,21,25,27,69,93,151,202,122,123,89,49,31,27,26,32,63,96,176,175,154,143,91,38,22,25,25,32,54,61,132,150,147,143,94,52,32,27,28,28,70,110,175,215,191,173,114,60,31,28,29,30,63,105,172,236,181,158,102,47,32,28,28,32,62,104,179,208,174,171,86,63,30,28,30,28,59,102,170,153,166,142,87,52,18,30,27,30,60,84,137,181,207,162,110,51,33,36,19,30,46,106,186,179,177,167,88,49,25,25,29,33,61,108,160,242,229,191,127,66,47,36,26,29,51,100,142,219,186,144,107,62,35,27,28,31,64,127,203,269,234,194,134,71,45,33,25,37,62,115,190,255,221,158,103,67,53,34,32,41,80,180,264,339,293,240,165,80,48,37,34,43,78,195,338,421,361,363,206,112,55,41,41,54,105,249,350,526,529,404,224,95,71,49,48,48,145,246,315,436,388,330,255,136,60,50,44,56,133,229,449,447,395,426,235,135,76,52,54,58,85,264,520,592,411,394,277,116,75,50,55,61,171,385,492,566,511,423,260,167,83,49,49,64,141,354,467,498,461,371,283,164,72,54,53,67,121.94,272,424,562,501]},"columns":[{"accessor":"date","name":"date","type":"Date"},{"accessor":"value","name":"value","type":"numeric"}],"defaultPageSize":10,"paginationType":"numbers","showPageInfo":true,"minRows":1,"outlined":true,"dataKey":"d55041ecb502143dc1abc5ce1a8d58c0","nested":true},"children":[]}]},{"name":"div","attribs":{"style":{"padding":"10px"}},"children":[{"name":"Reactable","attribs":{"data":{"date":["1989-01-01","1989-02-01","1989-03-01","1989-04-01","1989-05-01","1989-06-01","1989-07-01","1989-08-01","1989-09-01","1989-10-01","1989-11-01","1989-12-01","1990-01-01","1990-02-01","1990-03-01","1990-04-01","1990-05-01","1990-06-01","1990-07-01","1990-08-01","1990-09-01","1990-10-01","1990-11-01","1990-12-01","1991-01-01","1991-02-01","1991-03-01","1991-04-01","1991-05-01","1991-06-01","1991-07-01","1991-08-01","1991-09-01","1991-10-01","1991-11-01","1991-12-01","1992-01-01","1992-02-01","1992-03-01","1992-04-01","1992-05-01","1992-06-01","1992-07-01","1992-08-01","1992-09-01","1992-10-01","1992-11-01","1992-12-01","1993-01-01","1993-02-01","1993-03-01","1993-04-01","1993-05-01","1993-06-01","1993-07-01","1993-08-01","1993-09-01","1993-10-01","1993-11-01","1993-12-01","1994-01-01","1994-02-01","1994-03-01","1994-04-01","1994-05-01","1994-06-01","1994-07-01","1994-08-01","1994-09-01","1994-10-01","1994-11-01","1994-12-01","1995-01-01","1995-02-01","1995-03-01","1995-04-01","1995-05-01","1995-06-01","1995-07-01","1995-08-01","1995-09-01","1995-10-01","1995-11-01","1995-12-01","1996-01-01","1996-02-01","1996-03-01","1996-04-01","1996-05-01","1996-06-01","1996-07-01","1996-08-01","1996-09-01","1996-10-01","1996-11-01","1996-12-01","1997-01-01","1997-02-01","1997-03-01","1997-04-01","1997-05-01","1997-06-01","1997-07-01","1997-08-01","1997-09-01","1997-10-01","1997-11-01","1997-12-01","1998-01-01","1998-02-01","1998-03-01","1998-04-01","1998-05-01","1998-06-01","1998-07-01","1998-08-01","1998-09-01","1998-10-01","1998-11-01","1998-12-01","1999-01-01","1999-02-01","1999-03-01","1999-04-01","1999-05-01","1999-06-01","1999-07-01","1999-08-01","1999-09-01","1999-10-01","1999-11-01","1999-12-01","2000-01-01","2000-02-01","2000-03-01","2000-04-01","2000-05-01","2000-06-01","2000-07-01","2000-08-01","2000-09-01","2000-10-01","2000-11-01","2000-12-01","2001-01-01","2001-02-01","2001-03-01","2001-04-01","2001-05-01","2001-06-01","2001-07-01","2001-08-01","2001-09-01","2001-10-01","2001-11-01","2001-12-01","2002-01-01","2002-02-01","2002-03-01","2002-04-01","2002-05-01","2002-06-01","2002-07-01","2002-08-01","2002-09-01","2002-10-01","2002-11-01","2002-12-01","2003-01-01","2003-02-01","2003-03-01","2003-04-01","2003-05-01","2003-06-01","2003-07-01","2003-08-01","2003-09-01","2003-10-01","2003-11-01","2003-12-01","2004-01-01","2004-02-01","2004-03-01","2004-04-01","2004-05-01","2004-06-01","2004-07-01","2004-08-01","2004-09-01","2004-10-01","2004-11-01","2004-12-01","2005-01-01","2005-02-01","2005-03-01","2005-04-01","2005-05-01","2005-06-01","2005-07-01","2005-08-01","2005-09-01","2005-10-01","2005-11-01","2005-12-01","2006-01-01","2006-02-01","2006-03-01","2006-04-01","2006-05-01","2006-06-01","2006-07-01","2006-08-01","2006-09-01","2006-10-01","2006-11-01","2006-12-01","2007-01-01","2007-02-01","2007-03-01","2007-04-01","2007-05-01","2007-06-01","2007-07-01","2007-08-01","2007-09-01","2007-10-01","2007-11-01","2007-12-01","2008-01-01","2008-02-01","2008-03-01","2008-04-01","2008-05-01","2008-06-01","2008-07-01","2008-08-01","2008-09-01","2008-10-01","2008-11-01","2008-12-01","2009-01-01","2009-02-01","2009-03-01","2009-04-01","2009-05-01","2009-06-01","2009-07-01","2009-08-01","2009-09-01","2009-10-01","2009-11-01","2009-12-01","2010-01-01","2010-02-01","2010-03-01","2010-04-01","2010-05-01","2010-06-01","2010-07-01","2010-08-01","2010-09-01","2010-10-01","2010-11-01","2010-12-01","2011-01-01","2011-02-01","2011-03-01","2011-04-01","2011-05-01","2011-06-01","2011-07-01","2011-08-01","2011-09-01","2011-10-01","2011-11-01","2011-12-01","2012-01-01","2012-02-01","2012-03-01","2012-04-01","2012-05-01","2012-06-01","2012-07-01","2012-08-01","2012-09-01","2012-10-01","2012-11-01","2012-12-01","2013-01-01","2013-02-01","2013-03-01","2013-04-01","2013-05-01","2013-06-01","2013-07-01","2013-08-01","2013-09-01","2013-10-01","2013-11-01","2013-12-01","2014-01-01","2014-02-01","2014-03-01","2014-04-01","2014-05-01","2014-06-01","2014-07-01","2014-08-01","2014-09-01","2014-10-01","2014-11-01","2014-12-01","2015-01-01","2015-02-01","2015-03-01","2015-04-01","2015-05-01","2015-06-01","2015-07-01","2015-08-01","2015-09-01","2015-10-01","2015-11-01","2015-12-01","2016-01-01","2016-02-01","2016-03-01","2016-04-01","2016-05-01","2016-06-01","2016-07-01","2016-08-01","2016-09-01","2016-10-01","2016-11-01","2016-12-01","2017-01-01","2017-02-01","2017-03-01","2017-04-01","2017-05-01","2017-06-01","2017-07-01","2017-08-01","2017-09-01","2017-10-01","2017-11-01","2017-12-01","2018-01-01","2018-02-01","2018-03-01","2018-04-01","2018-05-01","2018-06-01","2018-07-01","2018-08-01","2018-09-01","2018-10-01","2018-11-01","2018-12-01","2019-01-01","2019-02-01","2019-03-01","2019-04-01","2019-05-01","2019-06-01","2019-07-01","2019-08-01","2019-09-01","2019-10-01","2019-11-01","2019-12-01","2020-01-01","2020-02-01","2020-03-01","2020-04-01","2020-05-01","2020-06-01","2020-07-01","2020-08-01","2020-09-01","2020-10-01","2020-11-01","2020-12-01","2021-01-01","2021-02-01"],"value":[3128,2971,1957,1106,829,748,531,478,555,703,1400,2359,2988,3010,2208,1127,862,775,562,520,521,717,1270,2593,3919,2512,2116,1876,1208,853,622,546,547,680,1315,2941,3525,2611,2094,1394,803,695,671,529,608,727,1226,3302,3892,3157,2715,1503,1087,910,600,612,651,804,1492,3261,3597,3331,2505,1474,1151,883,669,587,632,829,1751,3855,3927,3102,2189,2156,1568,1087,801,655,677,817,1349,2357,3744,3264,2903,1884,1264,1011,779,678,732,894,2069,3386,4490,3843,3187,2027,1401,985,891,781,805,1024,1925,3884,5025,4149,3809,2826,1884,1487,977,813,824,1367,2526,4335,4935,4309,3331,2704,1843,1233,940,921,953,1208,1998,4396,4985,3863,3711,2027,1568,1184,1009,932,1085,1399,3228,4950,5541,5420,3978,2473,1641,1175,1042,996,1034,1245,2188,5877,5871,5596,3726,2405,1753,1296,1033,940,1081,1428,2603,4226,5431,4563,4059,2814,2114,1221,1114,994,1075,1272,2816,5374,6772,5908,4037,2025,1724,1419,1190,1083,1216,1587,3498,6075,6833,5631,3894,3081,2044,1633,1173,1115,1279,1623,2513,5578,6188,5415,5206,3334,1816,1515,1237,1147,1287,1878,2823,6092,8093,5982,4061,2447,1969,1491,1270,1155,1267,1880,2637,5834,8262,6795,4415,2774,1956,1620,1261,1142,1226,1683,2491,5038,7457,5654,4596,2974,1862,1475,1272,1147,1213,1708,2898,6484,7471,5926,4741,3255,2286,1690,1248,1102,1227,1524,3161,5748,7445,5946,4580,2953,2059,1643,1278,1180,1212,1616,3785,6896,7170,5815,4325,2717,1774,1504,1377,1054,1199,1513,3143,5479,9120,6103,4077,2476,1744,1395,1212,1106,1243,2210,3411,7568,6886,5205,3533,2585,1824,1438,1257,1168,1206,1556,3016,5459,7046,4287,3384,2366,1901,1497,1120,1189,1228,1449,4218,7344,8540,5658,3524,2500,1993,1518,1269,1208,1387,1810,2891,6777,8578,6256,4396,2794,2022,1600,1310,1153,1476,2035,2973,6316,6655,6123,5723,2891,2003,1612,1256,1154,1408,2031,4052,6929,8520,8076,6324,3021,2254,1807,1453,1310,1520,2427,3862,7356,8302,6716,5342,3572,2327,1963,1584,1316,1533,2046,4009,7207,8202,6982]},"columns":[{"accessor":"date","name":"date","type":"Date"},{"accessor":"value","name":"value","type":"numeric"}],"defaultPageSize":10,"paginationType":"numbers","showPageInfo":true,"minRows":1,"outlined":true,"dataKey":"dc4c2e44d8de6d2cd3aec3bb6518e71b","nested":true},"children":[]}]},{"name":"div","attribs":{"style":{"padding":"10px"}},"children":[{"name":"Reactable","attribs":{"data":{"date":["1989-01-01","1989-02-01","1989-03-01","1989-04-01","1989-05-01","1989-06-01","1989-07-01","1989-08-01","1989-09-01","1989-10-01","1989-11-01","1989-12-01","1990-01-01","1990-02-01","1990-03-01","1990-04-01","1990-05-01","1990-06-01","1990-07-01","1990-08-01","1990-09-01","1990-10-01","1990-11-01","1990-12-01","1991-01-01","1991-02-01","1991-03-01","1991-04-01","1991-05-01","1991-06-01","1991-07-01","1991-08-01","1991-09-01","1991-10-01","1991-11-01","1991-12-01","1992-01-01","1992-02-01","1992-03-01","1992-04-01","1992-05-01","1992-06-01","1992-07-01","1992-08-01","1992-09-01","1992-10-01","1992-11-01","1992-12-01","1993-01-01","1993-02-01","1993-03-01","1993-04-01","1993-05-01","1993-06-01","1993-07-01","1993-08-01","1993-09-01","1993-10-01","1993-11-01","1993-12-01","1994-01-01","1994-02-01","1994-03-01","1994-04-01","1994-05-01","1994-06-01","1994-07-01","1994-08-01","1994-09-01","1994-10-01","1994-11-01","1994-12-01","1995-01-01","1995-02-01","1995-03-01","1995-04-01","1995-05-01","1995-06-01","1995-07-01","1995-08-01","1995-09-01","1995-10-01","1995-11-01","1995-12-01","1996-01-01","1996-02-01","1996-03-01","1996-04-01","1996-05-01","1996-06-01","1996-07-01","1996-08-01","1996-09-01","1996-10-01","1996-11-01","1996-12-01","1997-01-01","1997-02-01","1997-03-01","1997-04-01","1997-05-01","1997-06-01","1997-07-01","1997-08-01","1997-09-01","1997-10-01","1997-11-01","1997-12-01","1998-01-01","1998-02-01","1998-03-01","1998-04-01","1998-05-01","1998-06-01","1998-07-01","1998-08-01","1998-09-01","1998-10-01","1998-11-01","1998-12-01","1999-01-01","1999-02-01","1999-03-01","1999-04-01","1999-05-01","1999-06-01","1999-07-01","1999-08-01","1999-09-01","1999-10-01","1999-11-01","1999-12-01","2000-01-01","2000-02-01","2000-03-01","2000-04-01","2000-05-01","2000-06-01","2000-07-01","2000-08-01","2000-09-01","2000-10-01","2000-11-01","2000-12-01","2001-01-01","2001-02-01","2001-03-01","2001-04-01","2001-05-01","2001-06-01","2001-07-01","2001-08-01","2001-09-01","2001-10-01","2001-11-01","2001-12-01","2002-01-01","2002-02-01","2002-03-01","2002-04-01","2002-05-01","2002-06-01","2002-07-01","2002-08-01","2002-09-01","2002-10-01","2002-11-01","2002-12-01","2003-01-01","2003-02-01","2003-03-01","2003-04-01","2003-05-01","2003-06-01","2003-07-01","2003-08-01","2003-09-01","2003-10-01","2003-11-01","2003-12-01","2004-01-01","2004-02-01","2004-03-01","2004-04-01","2004-05-01","2004-06-01","2004-07-01","2004-08-01","2004-09-01","2004-10-01","2004-11-01","2004-12-01","2005-01-01","2005-02-01","2005-03-01","2005-04-01","2005-05-01","2005-06-01","2005-07-01","2005-08-01","2005-09-01","2005-10-01","2005-11-01","2005-12-01","2006-01-01","2006-02-01","2006-03-01","2006-04-01","2006-05-01","2006-06-01","2006-07-01","2006-08-01","2006-09-01","2006-10-01","2006-11-01","2006-12-01","2007-01-01","2007-02-01","2007-03-01","2007-04-01","2007-05-01","2007-06-01","2007-07-01","2007-08-01","2007-09-01","2007-10-01","2007-11-01","2007-12-01","2008-01-01","2008-02-01","2008-03-01","2008-04-01","2008-05-01","2008-06-01","2008-07-01","2008-08-01","2008-09-01","2008-10-01","2008-11-01","2008-12-01","2009-01-01","2009-02-01","2009-03-01","2009-04-01","2009-05-01","2009-06-01","2009-07-01","2009-08-01","2009-09-01","2009-10-01","2009-11-01","2009-12-01","2010-01-01","2010-02-01","2010-03-01","2010-04-01","2010-05-01","2010-06-01","2010-07-01","2010-08-01","2010-09-01","2010-10-01","2010-11-01","2010-12-01","2011-01-01","2011-02-01","2011-03-01","2011-04-01","2011-05-01","2011-06-01","2011-07-01","2011-08-01","2011-09-01","2011-10-01","2011-11-01","2011-12-01","2012-01-01","2012-02-01","2012-03-01","2012-04-01","2012-05-01","2012-06-01","2012-07-01","2012-08-01","2012-09-01","2012-10-01","2012-11-01","2012-12-01","2013-01-01","2013-02-01","2013-03-01","2013-04-01","2013-05-01","2013-06-01","2013-07-01","2013-08-01","2013-09-01","2013-10-01","2013-11-01","2013-12-01","2014-01-01","2014-02-01","2014-03-01","2014-04-01","2014-05-01","2014-06-01","2014-07-01","2014-08-01","2014-09-01","2014-10-01","2014-11-01","2014-12-01","2015-01-01","2015-02-01","2015-03-01","2015-04-01","2015-05-01","2015-06-01","2015-07-01","2015-08-01","2015-09-01","2015-10-01","2015-11-01","2015-12-01","2016-01-01","2016-02-01","2016-03-01","2016-04-01","2016-05-01","2016-06-01","2016-07-01","2016-08-01","2016-09-01","2016-10-01","2016-11-01","2016-12-01","2017-01-01","2017-02-01","2017-03-01","2017-04-01","2017-05-01","2017-06-01","2017-07-01","2017-08-01","2017-09-01","2017-10-01","2017-11-01","2017-12-01","2018-01-01","2018-02-01","2018-03-01","2018-04-01","2018-05-01","2018-06-01","2018-07-01","2018-08-01","2018-09-01","2018-10-01","2018-11-01","2018-12-01","2019-01-01","2019-02-01","2019-03-01","2019-04-01","2019-05-01","2019-06-01","2019-07-01","2019-08-01","2019-09-01","2019-10-01","2019-11-01","2019-12-01","2020-01-01","2020-02-01","2020-03-01","2020-04-01","2020-05-01","2020-06-01","2020-07-01","2020-08-01","2020-09-01","2020-10-01","2020-11-01","2020-12-01","2021-01-01","2021-02-01"],"value":[5838,5621,5179,3608,2263,1001,741,695,824,1738,3240,6382,6858,4690,4174,3403,1747,1055,724,696,800,1353,3031,4069,5561,5527,4858,2876,1372,707,629,622,765,1738,3210,4722,6183,6231,4328,4038,2076,1105,683,661,819,1899,3120,4146,5220,5960,5767,3560,1608,962,533,620,740,1818,3347,5072,7397,6344,5136,3281,1841,926,541,625,789,1511,2462,4348,5783,6546,4592,3173,1776,702,574,560,740,1441,3626,5867,6958,6602,5495,3877,1652,817,590,537,696,1609,3391,5166,5908,5572,4273,3386,2223,952,492,598,776,1737,4061,6017,5676,4894,4540,2879,1278,670,513,526,623,1300,2791,3974,6202,4957,5443,2957,1398,657,527,505,681,1339,2541,4195,5832,6279,3818,2491,1898,747,520,535,599,1372,2177,5331,6696,5275,4997,3394,963,442,386,448,752,1527,3089,3970,4915,4814,4528,2641,1609,533,537,448,549,1556,3357,5306,6785,6223,4385,2285,1171,600,477,443,680,1816,2379,4964,6178,6569,4455,2958,1262,484,486,449,491,1065,1959,3974,5162,5469,5157,2534,1660,636,399,396,419,756,2339,4868,4679,4570,4193,2280,1145,618,355,365,500,1159,2623,3597,4242,5694,4898,2305,736,355,363,331,343,889,2568,3806,5137,4779,3983,1765,993,425,364,369,440,1519,3186,4557,5706,4672,3336,1937,755,340,370,348,503,1636,2128,4442,5549,5003,2971,1496,807,399,350,387,436,1239,2796,5587,5695,4049,3538,1740,801,523,363,333,462,1374,2362,3832,4430,4096,1961,1907,458,327,233,379,631,1363,3300,3454,4530,4486,4560,1982,824,467,331,362,549,1356,3198,3870,5909,4950,4484,1972,913,466,360,360,517,1147,3249,3929,5121,5640,4563,1631,668,416,243,337,385,1235,2120,2449,5275,4160,2617,1784,726,371,363,323,360,884,2265,4083,4081,3118,3489,1372,758,325,356,304,485,1014,2610,4473,5522,3644,4242,2439,592,385,330,297,348,1311,3135,4011,5017,3677,3842,1355,654,314,331,343,297,1089,3172,3758,4223,3987,2660,1931,940,669,322,315,500,1072,2085,3904,4954,4689]},"columns":[{"accessor":"date","name":"date","type":"Date"},{"accessor":"value","name":"value","type":"numeric"}],"defaultPageSize":10,"paginationType":"numbers","showPageInfo":true,"minRows":1,"outlined":true,"dataKey":"9c4a8051963a1b8e6a83e09037a76c12","nested":true},"children":[]}]}]},{"accessor":"state","name":"state","type":"character"},{"accessor":"nested_column","name":"nested_column","type":"list"}],"defaultPageSize":4,"paginationType":"numbers","showPageInfo":true,"minRows":1,"dataKey":"0ebae70d64db6fe4d648a75fccff0d9b"},"children":[]},"class":"reactR_markup"},"evals":[],"jsHooks":[]}</script> --- ## Receta 🌮 ```r receta <- recipe(value ~ date, data = data %>% select(-state)) %>% step_timeseries_signature(date) %>% step_rm(contains("iso"), contains("minute"), contains("hour"), contains("am.pm"), contains("xts"), contains("second"), date_index.num, date_wday, date_month) ``` --- ## Modelos 🚀 Definición de modelos ```r # Modelo: tbats m_tbats <-seasonal_reg() %>% set_engine("tbats") # Modelo stlm_arima m_seasonal <- seasonal_reg() %>% set_engine("stlm_arima") # Workflow: prophet boosted m_prophet_boost <- workflow() %>% add_recipe(receta) %>% add_model( prophet_boost(mode='regression') %>% set_engine("prophet_xgboost") ) ``` --- ## Modeltime Multifit ✨ <img src="images/gif_jack.gif" width="50%" style="display: block; margin: auto;" /> ```r model_table <- modeltime_multifit(serie = nest_data, .prop = 0.8, m_tbats, m_seasonal, m_prophet_boost ) ``` --- ## Modeltimetable * **Table time** ```r model_table$table_time ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["state"],"name":[1],"type":["chr"],"align":["left"]},{"label":["nested_column"],"name":[2],"type":["list"],"align":["right"]},{"label":["m_tbats"],"name":[3],"type":["list"],"align":["right"]},{"label":["m_seasonal"],"name":[4],"type":["list"],"align":["right"]},{"label":["m_prophet_boost"],"name":[5],"type":["list"],"align":["right"]},{"label":["nested_model"],"name":[6],"type":["list"],"align":["right"]},{"label":["calibration"],"name":[7],"type":["list"],"align":["right"]}],"data":[{"1":"Hawaii","2":"<tibble[,2]>","3":"<S3: _tbats_fit_impl>","4":"<S3: _stlm_arima_fit_impl>","5":"<S3: workflow>","6":"<mdl_tm_t[,3]>","7":"<mdl_tm_t[,5]>"},{"1":"Maine","2":"<tibble[,2]>","3":"<S3: _tbats_fit_impl>","4":"<S3: _stlm_arima_fit_impl>","5":"<S3: workflow>","6":"<mdl_tm_t[,3]>","7":"<mdl_tm_t[,5]>"},{"1":"Nevada","2":"<tibble[,2]>","3":"<S3: _tbats_fit_impl>","4":"<S3: _stlm_arima_fit_impl>","5":"<S3: workflow>","6":"<mdl_tm_t[,3]>","7":"<mdl_tm_t[,5]>"},{"1":"West Virginia","2":"<tibble[,2]>","3":"<S3: _tbats_fit_impl>","4":"<S3: _stlm_arima_fit_impl>","5":"<S3: workflow>","6":"<mdl_tm_t[,3]>","7":"<mdl_tm_t[,5]>"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[6],"max":[6]},"pages":{}}} </script> </div> -- ```r model_table$table_time$nested_model[[1]] ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":[".model_id"],"name":[1],"type":["int"],"align":["right"]},{"label":[".model"],"name":[2],"type":["list"],"align":["right"]},{"label":[".model_desc"],"name":[3],"type":["chr"],"align":["left"]}],"data":[{"1":"1","2":"<S3: _tbats_fit_impl>","3":"TBATS(1, {0,0}, -, {<12,5>})"},{"1":"2","2":"<S3: _stlm_arima_fit_impl>","3":"SEASONAL DECOMP: ARIMA(0,1,1)"},{"1":"3","2":"<S3: workflow>","3":"PROPHET W/ XGBOOST ERRORS"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[6],"max":[6]},"pages":{}}} </script> </div> --- ## Calibración de modelos 🔧 Se verifica el **rendimiento** de los modelos sobre la partición de test. * Verificación de métricas 🎯 ```r model_table$models_accuracy ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["name_serie"],"name":[1],"type":["chr"],"align":["left"]},{"label":[".model_id"],"name":[2],"type":["int"],"align":["right"]},{"label":[".model_desc"],"name":[3],"type":["chr"],"align":["left"]},{"label":[".type"],"name":[4],"type":["chr"],"align":["left"]},{"label":["mae"],"name":[5],"type":["dbl"],"align":["right"]},{"label":["mape"],"name":[6],"type":["dbl"],"align":["right"]},{"label":["mase"],"name":[7],"type":["dbl"],"align":["right"]},{"label":["smape"],"name":[8],"type":["dbl"],"align":["right"]},{"label":["rmse"],"name":[9],"type":["dbl"],"align":["right"]},{"label":["rsq"],"name":[10],"type":["dbl"],"align":["right"]}],"data":[{"1":"Hawaii","2":"1","3":"TBATS(1, {0,0}, -, {<12,5>})","4":"Test","5":"2.048344","6":"4.239269","7":"0.5997054","8":"4.213804","9":"2.580558","10":"0.6580835"},{"1":"Hawaii","2":"2","3":"SEASONAL DECOMP: ARIMA(0,1,1)","4":"Test","5":"2.082337","6":"4.306734","7":"0.6096577","8":"4.304328","9":"2.530066","10":"0.6653430"},{"1":"Hawaii","2":"3","3":"PROPHET W/ XGBOOST ERRORS","4":"Test","5":"3.132737","6":"6.664286","7":"0.9171891","8":"6.379083","9":"3.720455","10":"0.6363483"},{"1":"Maine","2":"1","3":"TBATS(0, {2,2}, -, {<12,5>})","4":"Test","5":"62.628731","6":"20.682037","7":"0.7804519","8":"24.038519","9":"90.084881","10":"0.9317830"},{"1":"Maine","2":"2","3":"SEASONAL DECOMP: ARIMA(4,1,3) WITH DRIFT","4":"Test","5":"75.051502","6":"45.199655","7":"0.9352590","8":"37.520298","9":"94.063015","10":"0.9493728"},{"1":"Maine","2":"3","3":"PROPHET W/ XGBOOST ERRORS","4":"Test","5":"51.864392","6":"24.763482","7":"0.6463114","8":"24.454316","9":"77.319740","10":"0.8739811"},{"1":"Nevada","2":"1","3":"TBATS(0, {1,2}, 0.888, {<12,4>})","4":"Test","5":"564.120987","6":"13.962006","7":"0.4881914","8":"15.165033","9":"817.142143","10":"0.9324942"},{"1":"Nevada","2":"2","3":"SEASONAL DECOMP: ARIMA(1,1,3) WITH DRIFT","4":"Test","5":"387.735939","6":"11.854816","7":"0.3355474","8":"11.353737","9":"544.458176","10":"0.9518313"},{"1":"Nevada","2":"3","3":"PROPHET W/ XGBOOST ERRORS","4":"Test","5":"544.514213","6":"12.185886","7":"0.4712236","8":"13.252798","9":"826.694587","10":"0.9370876"},{"1":"West Virginia","2":"1","3":"TBATS(0.348, {4,2}, -, {<12,5>})","4":"Test","5":"338.931416","6":"20.826426","7":"0.4139079","8":"18.116444","9":"511.570278","10":"0.9240290"},{"1":"West Virginia","2":"2","3":"SEASONAL DECOMP: ARIMA(1,1,1)","4":"Test","5":"350.999385","6":"23.373315","7":"0.4286454","8":"20.195734","9":"507.059505","10":"0.9341292"},{"1":"West Virginia","2":"3","3":"PROPHET W/ XGBOOST ERRORS","4":"Test","5":"393.904332","6":"25.124042","7":"0.4810416","8":"28.680657","9":"546.377757","10":"0.9249577"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[6],"max":[6]},"pages":{}}} </script> </div> --- ## Proyección sobre test 🔬 ```r forecast_series <- modeltime_multiforecast( model_table$table_time, .prop = 0.9 ) ``` --- * **Verificación visual** ```r forecast_series %>% select(state, nested_forecast) %>% unnest(nested_forecast) %>% group_by(state) %>% plot_modeltime_forecast() ``` 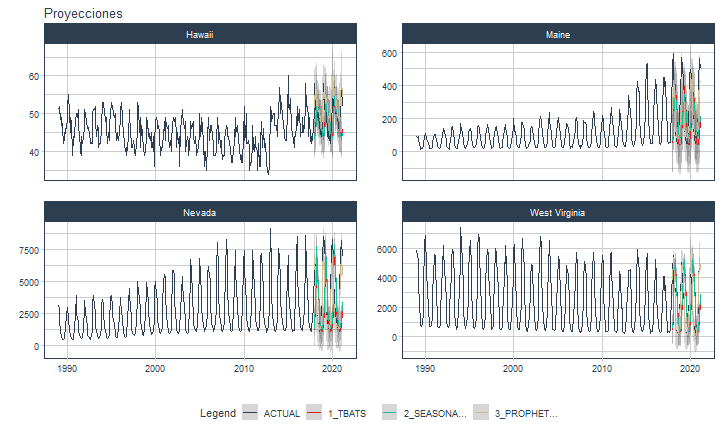<!-- --> --- ### Selección de modelos 🥇 Se selecciona el **mejor modelo** para cada serie en función a una métrica. ```r best_models <- modeltime_multibestmodel( .table = forecast_series, .metric = "mae" ) ``` <img src="images/gif_minon_1.gif" width="30%" style="display: block; margin: auto;" /> --- ```r best_models %>% select(state, nested_forecast) %>% unnest(nested_forecast) %>% group_by(state) %>% plot_modeltime_forecast() ``` 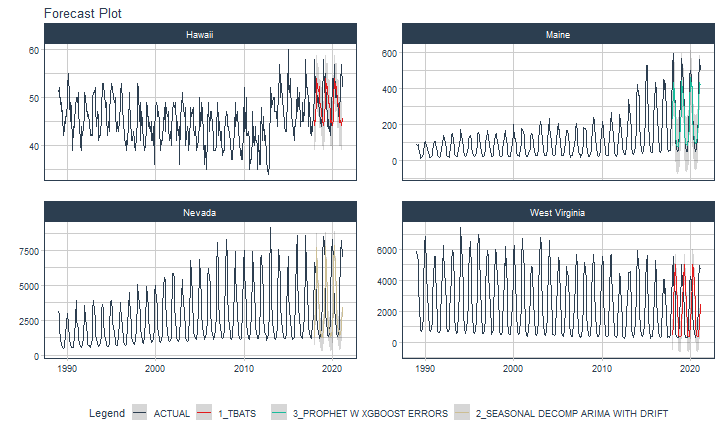<!-- --> --- ## Reajuste de los modelos 🌀 * **Se reajustan los modelos para todas las series completas (train + test)** ```r models_refit <- modeltime_multirefit(best_models) ``` -- **Proyección** 🔮 * **Se predicen los proximos 2 años para todas las series.** ```r forecast_final <- models_refit %>% modeltime_multiforecast(.h = "2 years") ``` -- --- **Visualización de la proyección a 2 años** ```r forecast_final %>% select(state, nested_forecast) %>% unnest(nested_forecast) %>% group_by(state) %>% plot_modeltime_forecast() ``` 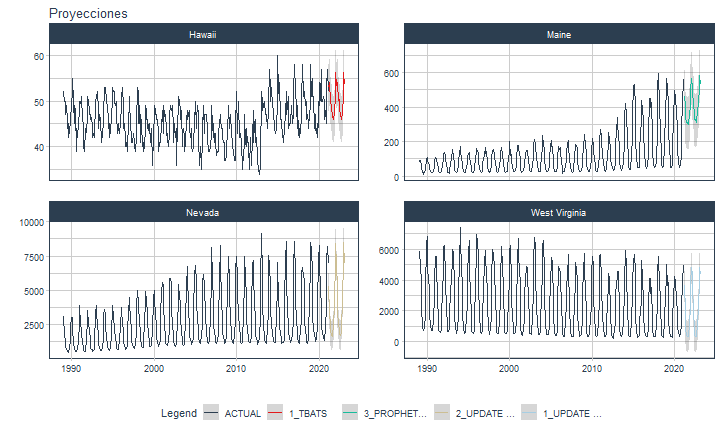<!-- --> --- # Workflowsets en múltiples series <img src="diagrama_wfs.png" width="6233" style="display: block; margin: auto;" /> --- ### Recetas 🌮 ```r # Receta base recipe_base <- recipe(value~date, data=data_hawaii) # Características según fecha recipe_date_extrafeatures <- recipe_base %>% step_date(date, features = c('month','year','quarter','semester')) # Resagos recipe_date_extrafeatures_lag <- recipe_date_extrafeatures %>% step_lag(value, lag = 1:6) %>% step_ts_impute(all_numeric(), period=365) # Fourier recipe_date_extrafeatures_fourier <-recipe_date_extrafeatures %>% step_fourier(date, period = 365/12, K = 1) ``` --- ### Modelos 🚀 ```r # prophet_xgboost prophet_boost <- prophet_boost(mode = 'regression') %>% set_engine("prophet_xgboost") # nnetar nnetar <- nnetar_reg() %>% set_engine("nnetar") #auto_arima_xgboost auto_arima_boost <- arima_boost() %>% set_engine('auto_arima_xgboost') ``` --- ### Workflowsets ✨ ```r wfsets <- workflow_set( preproc = list( base = recipe_base, extrafeatures = recipe_date_extrafeatures, extrafeatures_lag = recipe_date_extrafeatures_lag, extrafeatures_fourier = recipe_date_extrafeatures_fourier ), models = list( M_arima_boost = auto_arima_boost, M_prophet_boost = prophet_boost, M_nnetar = nnetar ), cross = TRUE ) ``` --- 👉 El objeto **wfsets** contiene todas las posibles combinaciones de recetas con modelos: ```r wfsets %>% rmarkdown::paged_table(list(rows.print = 6)) ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["wflow_id"],"name":[1],"type":["chr"],"align":["left"]},{"label":["info"],"name":[2],"type":["list"],"align":["right"]},{"label":["option"],"name":[3],"type":["list"],"align":["right"]},{"label":["result"],"name":[4],"type":["list"],"align":["right"]}],"data":[{"1":"base_M_arima_boost","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"base_M_prophet_boost","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"base_M_nnetar","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"extrafeatures_M_arima_boost","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"extrafeatures_M_prophet_boost","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"extrafeatures_M_nnetar","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"extrafeatures_lag_M_arima_boost","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"extrafeatures_lag_M_prophet_boost","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"extrafeatures_lag_M_nnetar","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"extrafeatures_fourier_M_arima_boost","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"extrafeatures_fourier_M_prophet_boost","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"},{"1":"extrafeatures_fourier_M_nnetar","2":"<tibble[,4]>","3":"<wrkflw__>","4":"<list [0]>"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[6],"max":[6]},"pages":{}}} </script> </div> --- ### Ajuste de modelos ⚙️ ```r wfs_multifit <- modeltime_wfs_multifit(serie = nest_data, .prop = 0.8, .wfs = wfsets) ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["state"],"name":[1],"type":["chr"],"align":["left"]},{"label":["nested_column"],"name":[2],"type":["list"],"align":["right"]},{"label":["base_M_arima_boost"],"name":[3],"type":["list"],"align":["right"]},{"label":["base_M_nnetar"],"name":[4],"type":["list"],"align":["right"]},{"label":["base_M_prophet_boost"],"name":[5],"type":["list"],"align":["right"]},{"label":["extrafeatures_fourier_M_arima_boost"],"name":[6],"type":["list"],"align":["right"]},{"label":["extrafeatures_fourier_M_nnetar"],"name":[7],"type":["list"],"align":["right"]},{"label":["extrafeatures_fourier_M_prophet_boost"],"name":[8],"type":["list"],"align":["right"]},{"label":["extrafeatures_lag_M_arima_boost"],"name":[9],"type":["list"],"align":["right"]},{"label":["extrafeatures_lag_M_nnetar"],"name":[10],"type":["list"],"align":["right"]},{"label":["extrafeatures_lag_M_prophet_boost"],"name":[11],"type":["list"],"align":["right"]},{"label":["extrafeatures_M_arima_boost"],"name":[12],"type":["list"],"align":["right"]},{"label":["extrafeatures_M_nnetar"],"name":[13],"type":["list"],"align":["right"]},{"label":["extrafeatures_M_prophet_boost"],"name":[14],"type":["list"],"align":["right"]},{"label":["nested_model"],"name":[15],"type":["list"],"align":["right"]},{"label":["calibration"],"name":[16],"type":["list"],"align":["right"]}],"data":[{"1":"Hawaii","2":"<tibble[,2]>","3":"<S3: workflow>","4":"<S3: workflow>","5":"<S3: workflow>","6":"<S3: workflow>","7":"<S3: workflow>","8":"<S3: workflow>","9":"<S3: workflow>","10":"<S3: workflow>","11":"<S3: workflow>","12":"<S3: workflow>","13":"<S3: workflow>","14":"<S3: workflow>","15":"<mdl_tm_t[,3]>","16":"<mdl_tm_t[,5]>"},{"1":"Maine","2":"<tibble[,2]>","3":"<S3: workflow>","4":"<S3: workflow>","5":"<S3: workflow>","6":"<S3: workflow>","7":"<S3: workflow>","8":"<S3: workflow>","9":"<S3: workflow>","10":"<S3: workflow>","11":"<S3: workflow>","12":"<S3: workflow>","13":"<S3: workflow>","14":"<S3: workflow>","15":"<mdl_tm_t[,3]>","16":"<mdl_tm_t[,5]>"},{"1":"Nevada","2":"<tibble[,2]>","3":"<S3: workflow>","4":"<S3: workflow>","5":"<S3: workflow>","6":"<S3: workflow>","7":"<S3: workflow>","8":"<S3: workflow>","9":"<S3: workflow>","10":"<S3: workflow>","11":"<S3: workflow>","12":"<S3: workflow>","13":"<S3: workflow>","14":"<S3: workflow>","15":"<mdl_tm_t[,3]>","16":"<mdl_tm_t[,5]>"},{"1":"West Virginia","2":"<tibble[,2]>","3":"<S3: workflow>","4":"<S3: workflow>","5":"<S3: workflow>","6":"<S3: workflow>","7":"<S3: workflow>","8":"<S3: workflow>","9":"<S3: workflow>","10":"<S3: workflow>","11":"<S3: workflow>","12":"<S3: workflow>","13":"<S3: workflow>","14":"<S3: workflow>","15":"<mdl_tm_t[,3]>","16":"<mdl_tm_t[,5]>"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[6],"max":[6]},"pages":{}}} </script> </div> --- **Performance según rsq de cada modelo en cada serie** .panelset[ .panel[.panel-name[Hawaii] 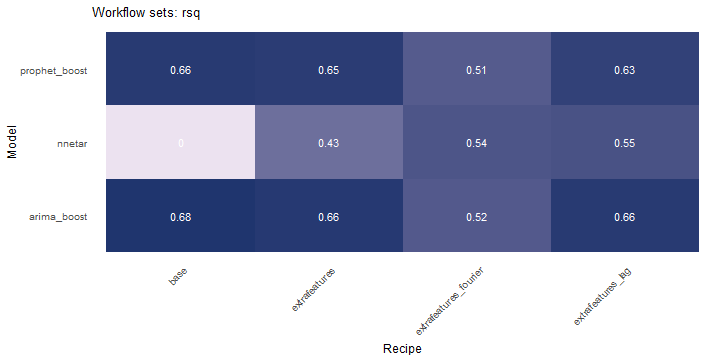<!-- --> ] .panel[.panel-name[Maine] 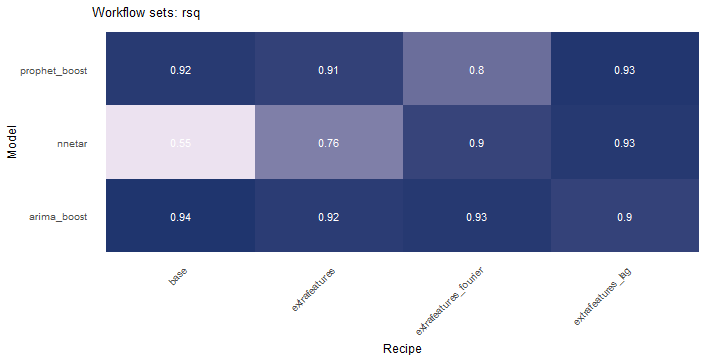<!-- --> ] .panel[.panel-name[Nevada] 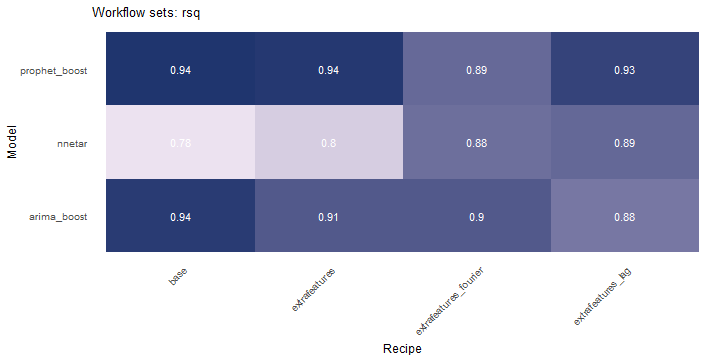<!-- --> ] .panel[.panel-name[West Virginia] 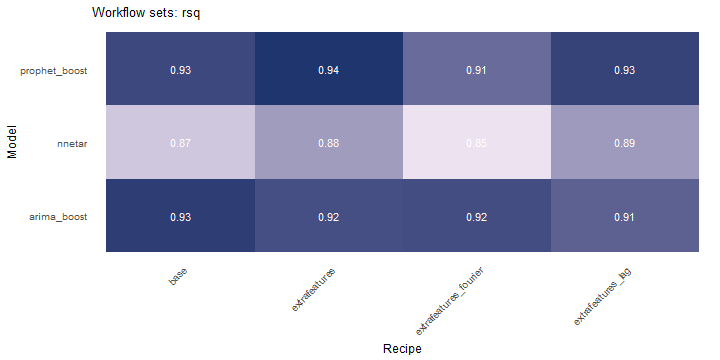<!-- --> ] ] --- ### Proyecciones 🔬 ```r wfs_multiforecast <- modeltime_wfs_multiforecast( wfs_multifit$table_time, .prop=0.8) ``` <img src="sknifedatar_files/figure-html/unnamed-chunk-80-1.png" style="display: block; margin: auto;" /> --- ### Selección del mejor modelo 🥇 ```r wfs_bests<- modeltime_wfs_multibestmodel( .table = wfs_multiforecast, .metric = "rsq", .minimize = FALSE ) ``` ### Reentrenamiento para todos los datos 🌀 ```r wfs_refit <- modeltime_wfs_multirefit(wfs_bests) ``` --- ### Proyecciones a 12 meses 🔮 ```r wfs_forecast <- modeltime_wfs_multiforecast(wfs_refit, .h = "12 month") ``` 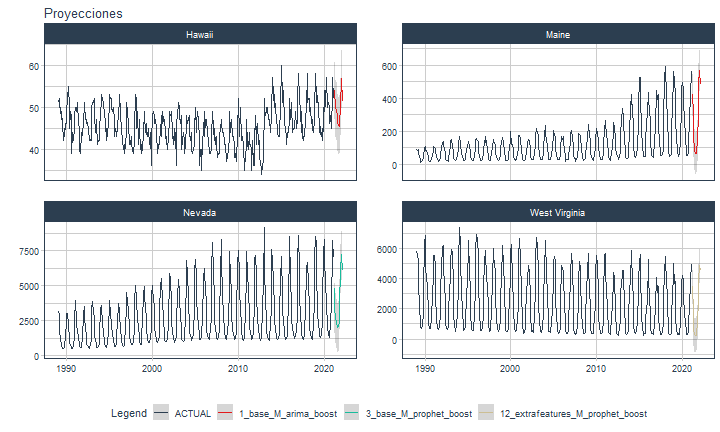<!-- --> --- <br> <br> # Automagic Tabs <br> <img src="images/gif_gato_tocadisco.gif" width="50%" style="display: block; margin: auto;" /> --- # ¿Por qué utilizar tabs? 🤔 Mostrar muchos gráficos 📈 o resultados de modelos 🤖 juntos puede generar confusión. Organizar los resultados en solapas permite centrar la atención en ciertos aspectos y no sobrecargar de información. .panelset[ .panel[.panel-name[👋 Hey!] Esta es la primera tab 🌟 Hacer click en las tabs para consejos no solicitados 🌟 👆 ] .panel[.panel-name[Consejo 1] <img src="https://media.tenor.com/images/be8a87467b75e9deaa6cfe8ad0b739a0/tenor.gif" width="50%" style="display: block; margin: auto;" /> ] .panel[.panel-name[Consejo 2] <img src="https://media.tenor.com/images/6a2cca305dfacae61c5668dd1687ad55/tenor.gif" width="50%" style="display: block; margin: auto;" /> ] .panel[.panel-name[Consejo 3] <img src="https://media.tenor.com/images/bfde5ad652b71fc9ded82c6ed760355b/tenor.gif" width="50%" style="display: block; margin: auto;" /> ] ] --- ## ¿Cómo se crean tabs manualmente? <img src="https://karbartolome-blog.netlify.app/posts/automagictabs/data/tabs.png" width="70%" style="display: block; margin: auto;" /> --- <br> <br> <br> <img src="images/gif_minon_2.gif" width="50%" style="display: block; margin: auto;" /> --- ## Generación automática de tabs 🙌 👉 **Código inline** , utilizando un dataframe anidado, que incluye una variable del resultado a presentar por tab ('ts_plots'), y una variable agrupadora ('state') ```r `r automagic_tabs(input_data = nest_plots_1, panel_name = "state", .output = "ts_plots")` ``` --- <img src="images/gif_bye.gif" width="30%" style="display: block; margin: auto;" /> ## Contactos ✉ Karina Bartolome [](https://twitter.com/karbartolome) [](https://www.linkedin.com/in/karinabartolome/) [](https://github.com/karbartolome) [](https://karbartolome-blog.netlify.app/) Rafael Zambrano [](https://twitter.com/rafa_zamr) [](https://www.linkedin.com/in/rafael-zambrano/) [](https://github.com/rafzamb) [](https://rafael-zambrano-blog-ds.netlify.app/)